|
数据地图因数据流转不清、管理低效等问题应运而生,旨在解决找数据难、血缘查看不便、故障排查慢等痛点。其具备全链路覆盖、精准搜索、多维度管理及链路分析(血缘追踪、异常排查、影响评估)等能力。实践中通过优化存储与算法提升效率,未来将拓展至降本、质量优化等场景,为数据全生命周期管理提供有力支撑
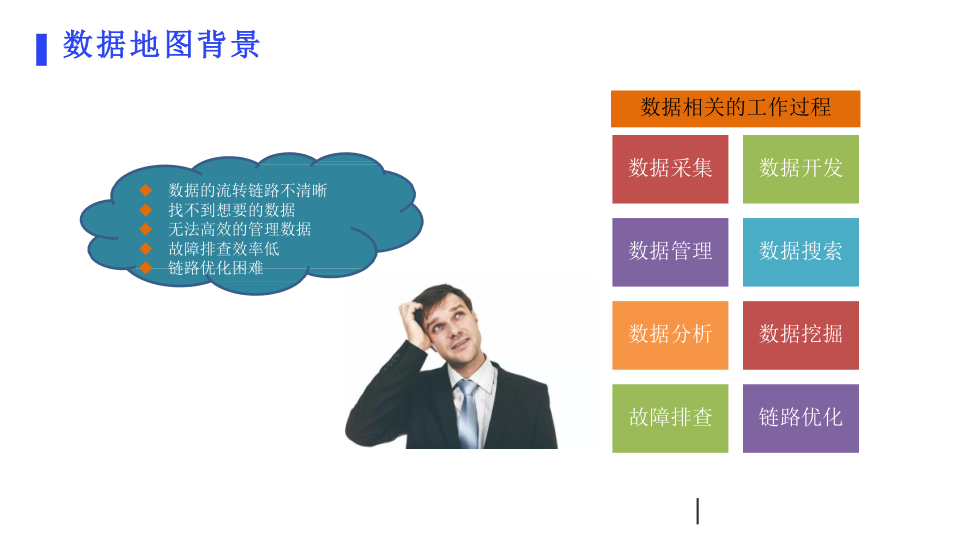
数据相关工作的困境
在数据采集、开发、管理、搜索、分析、挖掘、故障排查及链路优化等环节,常会遇到不少难题。比如数据流转链路不清晰,导致故障排查效率低,链路优化也困难;工作人员经常找不到想要的数据,没法高效管理数据,这些都制约了数据工作的开展。
数据地图的目标
数据地图就是为了解决上述问题而诞生的,它的目标是让我们能高效找到所需数据,方便查看各类数据血缘信息,高效管理数据,高效应对故障(包括排查故障、预估影响面及恢复时间),并且能根据不同需求场景看到不同的链路视角。
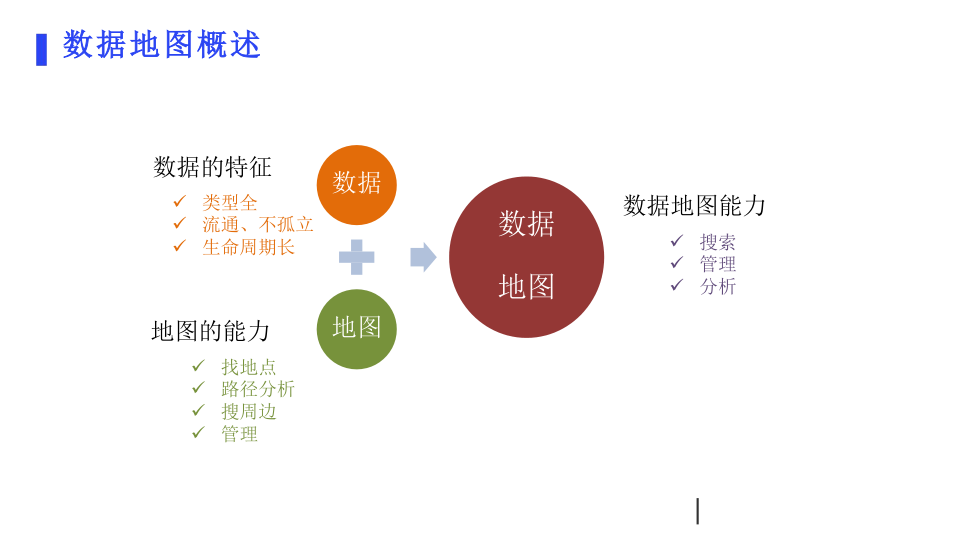
1.数据特征:数据有类型全、流通且不孤立、生命周期长等特征。这意味着数据涵盖各种类型,会在不同系统及环节中流通,并且在很长一段时间内都有价值。
2.地图能力:数据地图具备搜索、管理、分析等能力。就像现实中的地图能帮我们找地点、做路径分析、搜周边及管理地点信息一样,数据地图能帮我们在数据海洋中精准定位、分析数据间的关系,还能高效管理数据。
数据全链路实现了数据类型全、任务类型全、平台类型全、元数据类型全、血缘类型全。它把数据抽象成表和任务来统一管理,形成了从业务到业务的闭环。拿数据类型来说,涵盖 clickhouse、kafka、hbase 等;任务类型包括 spark、flinkJar、flinkSQL 等;平台类型则有数据开发平台、指标库、实时开发平台等。
数据搜索的目标是让找数据更精准、结果更匹配,并且对结果打分排序,让找数据更轻松。它支持从业务角度搜数据,搜索范围包括表、任务、指标、字段、报表、UDF 函数、文档、埋点等。搜索匹配方式有文本匹配、标签匹配、业务指标关联匹配、文档匹配、报表匹配等。搜索结果打分的影响因素中,加分项有当前负责人、下游数量、质量分、访问次数、公共层的表等;减分项有设置了替换表、临时表等。
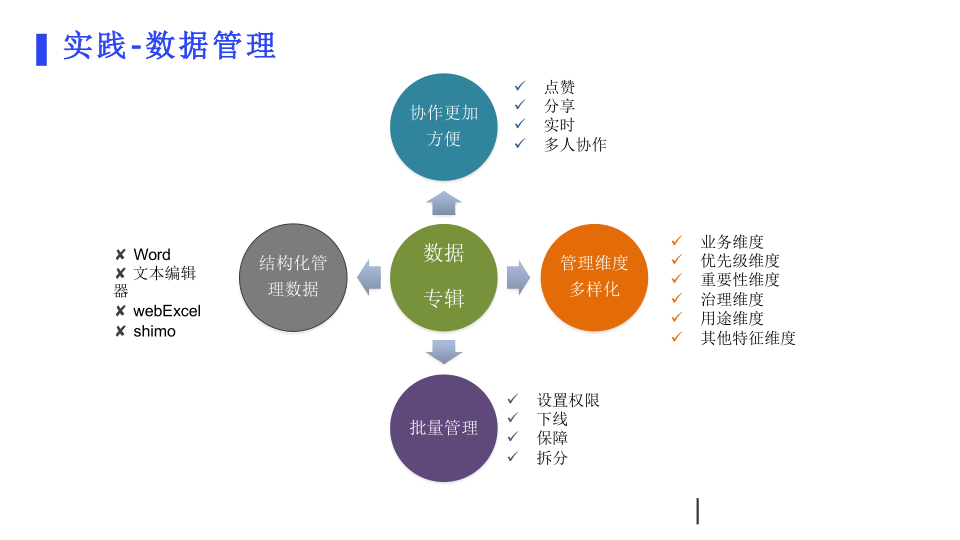
数据管理支持点赞、分享、实时多人协作。它从业务维度、优先级维度、重要性维度、治理维度、用途维度、其他特征维度等进行结构化管理,还能进行多样化批量管理,比如设置权限、下线、保障、拆分等。
血缘查看:可自由选择聚合维度,比如按表血缘、聚合维度、搜索节点、血缘日期等查看,还能自由切换上下游,节点按字典排序,方便查看表表血缘、表任务血缘等信息。
异常分析:目标表出现异常时,向上溯源能找到所有异常表,再经过剪枝优化,展示相对简单的路径,提高故障排查效率。
影响分析 & 产出时间预估:核心表出现故障时,能向下评估影响面,向上预估产出时间。历史运行时长取最近 7 天的中位数来预估。
链路优化:在成本过高、链路太长、产出时间太晚等场景下进行优化。就拿表任务血缘来说,可查看任务启动时间是否合理;根据字段血缘能判断表是否可替换等。
数据监控保障:包括定时任务及手动触发两种方式。定时任务扫描调度中心的任务,检查任务语法、输入表是否存在、输入表的字段是否存在等;手动触发可检测表下游的任务、表及字段等情况。
实践成果:数据地图在实践中成效显著。交互体验更流畅,接口响应时间小于 1 秒,效率提升 1-3 小时;使用情况上,UV 从 90 提升到 130,PV 从 2K 提升到 3.5K,数据类型达 29 种,任务类型 16 种,平台数 4+。
底层存储方式重构:血缘关系的底层存储从关系型数据库换成图数据库(如 neo4j),提高了数据存储及查询效率。
更多场景支持:数据地图的能力可协助降本,包括链路成本优化、质量优化、稳定性优化等,同时为下游应用提供保障。
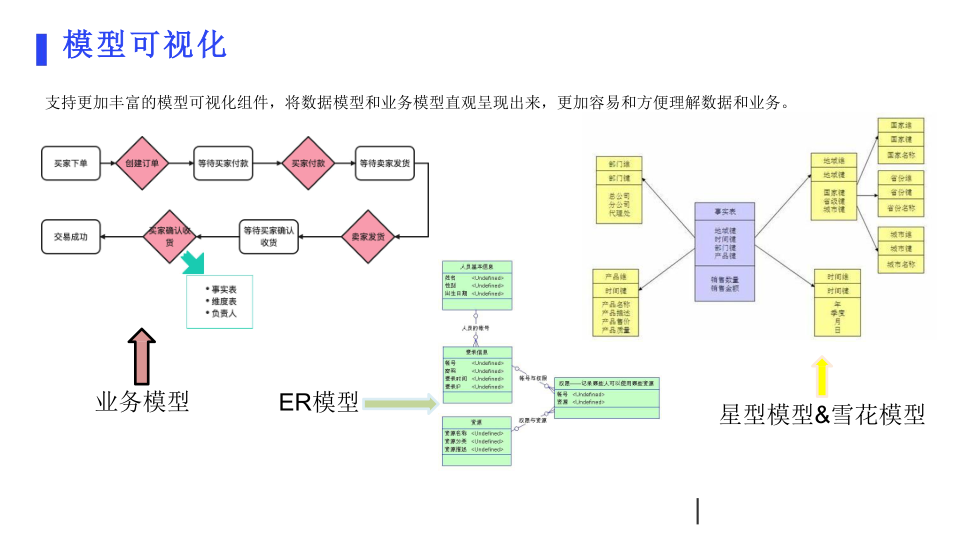
模型可视化:支持更丰富的模型可视化组件,能直观呈现数据模型及业务模型,让数据与业务更容易理解。
数据地图建设实践分享免费下载
https://research.fanruan.com/cio/2025-07-23/

|