|
正文开始前,给大家推荐一个《让数据成为生产力6.0》,本资料收录了帆软标杆用户在企业决策、流程优化、产品创新、市场拓展等方面的最新应用实践,更揭示了数据生产力对于提升企业核心竞争力的重大意义。
你是否遇见过这样的困境:Kafka 集群磁盘告急,想扩容却得连 CPU、内存一起买;跨区同步数据的账单高得惊人,却找不到拆分存储与计算的办法?
今天我们回到源头,聊聊 Kafka 诞生的初衷 —— 它为何能成为海量日志处理的标杆?当年让它成功的 "紧耦合" 设计,解决了什么关键问题?又为何在业务爆发后,反而成了技术团队的负担?
读懂这些,你会明白:任何技术的优势与局限,都藏在它诞生时的取舍里。这正是突破工具依赖、掌握架构逻辑的起点。
长期以来,Kafka 一直是分布式消息系统的标准。它被广泛用于服务之间的通信场景,使得某个服务无需直接与数百个其他服务通信。
“我把想说的内容写入一个 Kafka 的 Topic。如果你们想看,就从 Kafka 里消费它们。”
许多公司依赖 Kafka 协议。人们也使用 Kafka 将数据导入分析系统,比如数据仓库、数据湖或 Lakehouse。
假设我们想要通过 Kafka 的 Record 构建一个分析 Dashboard,我们就必须构建一条数据链路,使用 Kafka Connect、Spark 或 Flink 从 Kafka 的 Topic 消费数据,写入文件,并将这些文件推送到数据湖。
我们需要管理整个链路,并确保文件的物理布局是最优的。
除了 Kafka 开始使用 Object Storage 外,还有不少努力致力于简化 Kafka 的 Topic 数据到 Iceberg 表的转换过程。
本文将探讨 Kafka 架构从最初的 Shared Nothing 到 Shared Data 架构的演进。然后,我们将介绍 AutoMQ 推出的开源特性 Table Topic 背后的设计背景与实现原理,它帮助用户无需介入即可管理从 Kafka 到 Iceberg 的全链路。
LinkedIn 产生了大量日志数据,既包括用户行为事件(如登录、页面浏览和点击),也包括运维指标(服务调用延迟、错误或者系统资源使用情况)。
这些日志数据最初用于跟踪用户参与度和系统性能,现在也用于提升搜索相关性、推荐系统和广告投放效果等功能。
为满足 LinkedIn 在日志处理方面的需求,Jay Kreps 领导的团队构建了一个叫做 Kafka 的消息系统。这个系统融合了传统日志聚合器与发布 / 订阅消息系统的优势。它被设计成具有高吞吐和可扩展性。
Kafka 提供了一个类似消息系统的 API,允许应用程序实时消费日志事件。
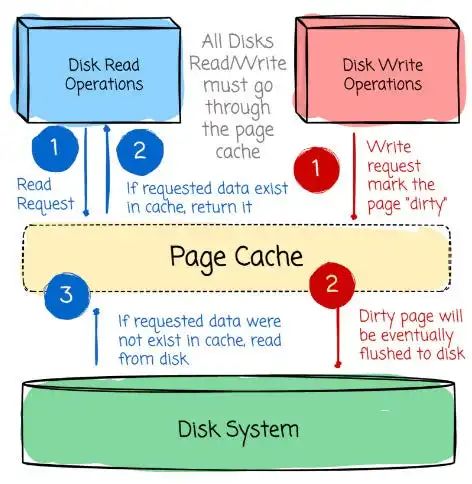
Kafka 的设计将计算和存储紧密耦合,这在当时是一种常见做法,因为那时的网络速度不像今天这么快。它通过利用操作系统的 Page Cache 和磁盘顺序访问模式实现高吞吐。
现代操作系统通常会使用未占用的内存(RAM)作为 Page Cache。这种缓存会存放频繁访问的磁盘数据,从而减少直接访问磁盘的次数。
因此,系统运行速度更快,降低了磁盘查找延迟带来的影响。
Kafka 的设计让写入(Producer 写数据)和读取(Consumer 读数据)都以顺序方式进行。
毫无疑问,随机访问比顺序访问在磁盘上慢很多,但如果是顺序访问,有时候磁盘性能甚至可以略微超过内存。
然而,Kafka 的初始设计很快暴露出一些局限。
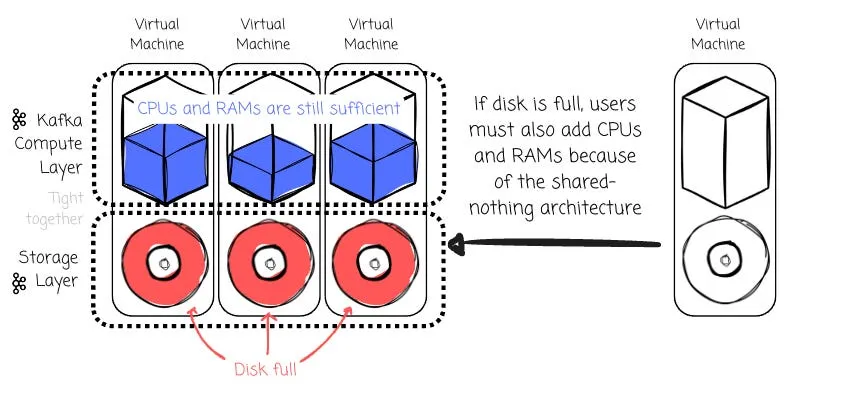
这种紧耦合设计意味着如果要扩展存储,就必须添加更多机器,这会导致资源利用效率低下。
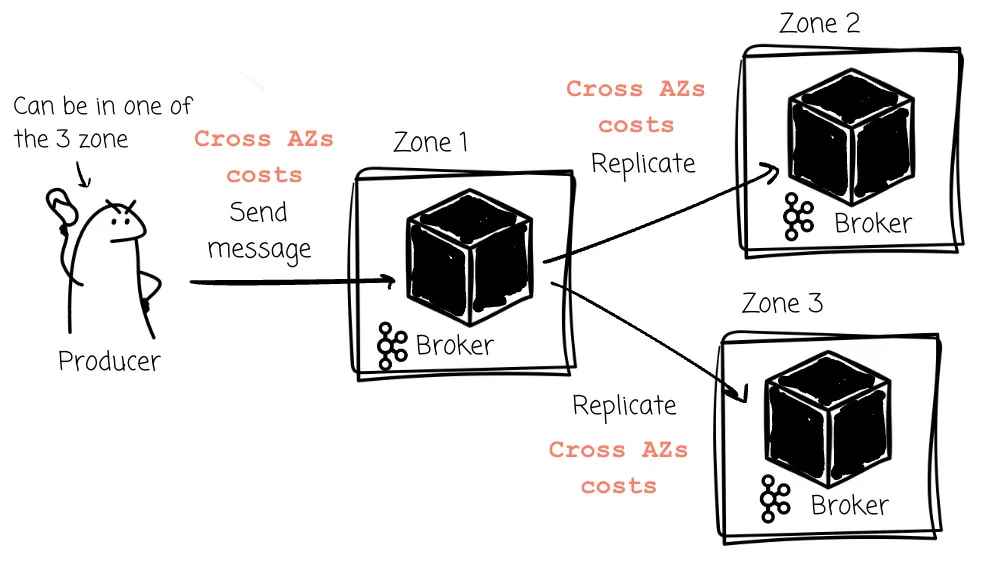
Kafka 的设计也依赖副本机制来保证 Record 的持久性。每个 Partition 有一个 Leader 和若干 Follower(用于存储副本)。所有写入都必须发给该 Partition 的 Leader,而读取可以由 Leader 或 Follower 提供。
当 Leader 接收到 Producer 发来的 Record 后,它会将这些 Record 同步到 Follower。这保证了数据的持久性与可用性。
由于 Kafka 的存储与计算是耦合的,所以每当集群成员发生变更时,数据必须在网络中进行迁移。
当公司在云上运行 Kafka 时,这些问题会进一步放大:
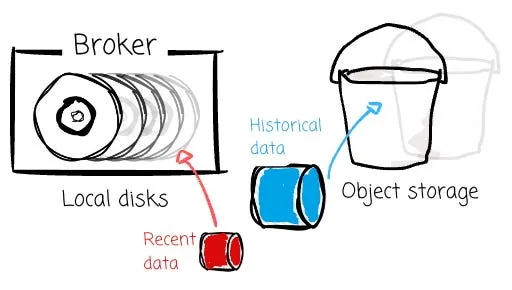
为了应对这些限制,Uber 提出了 Kafka 的 Tiered Storage(KIP-405),引入了两级存储体系:
-
本地存储(Broker 磁盘)保存最近的数据;
-
远程存储(HDFS/S3/GCS)保存历史数据。
然而,这个问题并没有被完全解决,因为 Broker 依然是有状态的。 |