|
9月19日,帆软第七届智数大会在重庆召开,大会以“数字无界,智见无限”为主题,汇聚了全球超过1000家企业的高层领导、CXO及数字化领域的专家,围绕企业数据应用话题展开研讨。大会主论坛上,帆软软件联合创始人季明华围绕“AI原生的可信数据分析产品组合”,提出以三大支柱构建可信数据分析能力,为企业数智转型提供工具支撑。
我今天要讲的是:AI原生的可信数据分析产品组合,接下来我从四个方面跟大家展开分享。
大模型应用发展趋势
从我们现在能洞察到的信息, 我们认大模型的应用有两个特点:一是越聚焦越有用,二是越高质量的数据越能提升准确性。
给大家分享一个AI面试官的案例,我们在招聘研发、测试、市场等岗位要人为判断候选人的技能跟企业需求是否匹配,需要投入很多招聘的人力。随着AI时代的到来,有很多创业者尝试用AI开发一个面试官,不幸的是很多企业在尝试过程中失败了。
但是有几家企业在AI面试上做的非常好,服务的场景非常聚焦。比如一个连锁咖啡店店员招聘场景,连锁的咖啡店每个地区都有不同的店长,这些店长招聘店员的时候会根据自己的喜好招聘店员,但这个人未必是适合整个连锁集团需求的。AI在这个场景下的切入就非常适,因为咖啡店店员的技能要求非常单一,考察岗位的意向,安全操作规范有没有,以及有没有学习技能的能力,这些考察项可以固化到相应的知识库里面,再给大模型进行一些预训练,让大模型判断候选人是否符合招聘需求。
这家企业在探索中逐个对比AI面试和真人面试的差距,不断优化升级,最终实现了从笔试到面试发OFFER全流程AI接管,替代了以前的人工面试。在这样一个非常聚焦的场景下,大模型可以完全替代掉原来人工的介入,从而极大降低了成本,这就是越聚焦越有用。
第二个例子是一家做报销应用的公司,跟他们技术交流的时候,他们说以前通过OCR识别票据,因为全球各个地方的票据格式差距大,OCR识别后还要加一道人工识别,OCR识别准确率只有80%-90%,人审核票据的工作依然减少不了。有了大模型后,结合原来人工校准后积累的高质量数据,对大模型进行训练,识别准确率提高到了99%以上,比人工审核的准确率还要高,几乎可以完全替代人力。这就是因为原来系统里积累的高质量数据,给了他们最大的帮助。
大模型+数据应用的现状
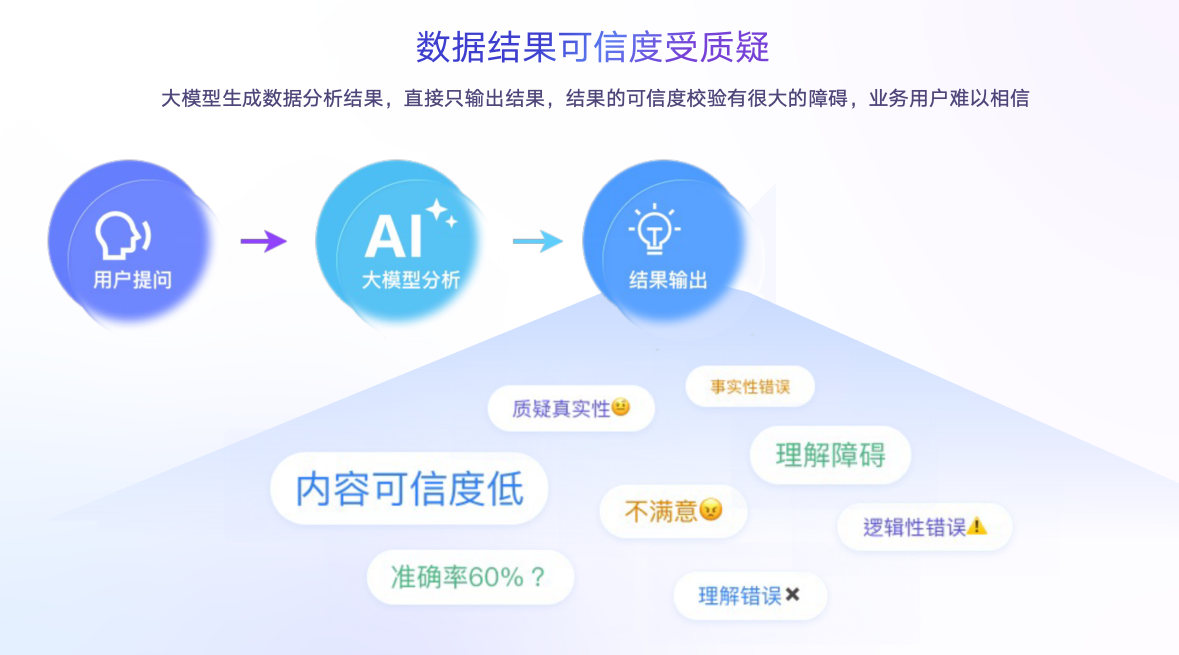
帆软也是围绕着上述两个特点去制定产品战略的。AI时代数据价值是被大模型放大的,我们都在想,AI时代,我们能不能直接把数据喂给大模型,大模型给出结果,我们拿着结果直接使用,这个想法是美好的,也是有可能实现的。但是我们在运用大模型的时候面临几个典型问题:
直接把数据给了大模型,大模型反馈的结果可信度无法探究,大模型本身是一个黑箱,无法对数据进行核查、校验它的过程是否符合我们业务需求,导致它最终生成的结果很难让业务去直接使用,内容可信度低,最后不得不放弃这种方式。
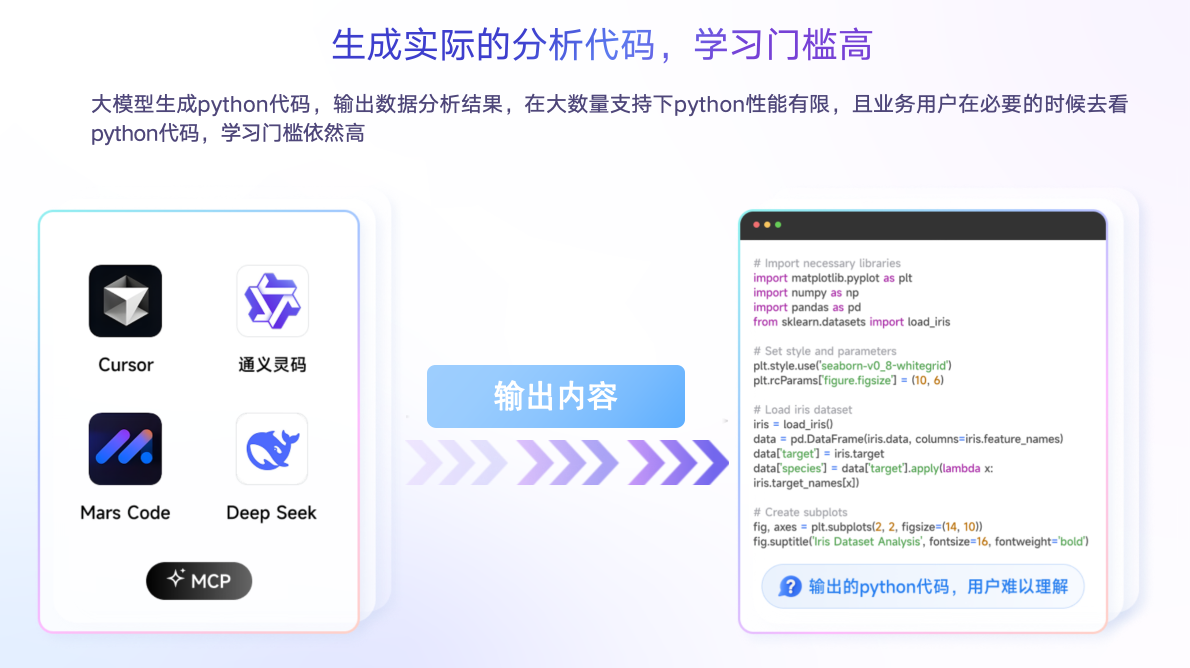
有没有别的办法?肯定是有的,大模型非常擅长写代码,并且代码准确率通常能够达到95%以上。但是它并不能解决两个普遍性的问题,一是企业级数据分析里,涉及到的数据量非常大,这种情况下,大模型很难支撑并且输出正确的结果。二是我们希望大模型能够降低大家做数据分析的门槛,但是它写出来的是代码,阅读理解的难度大,反而提高了数据分析的门槛。而用户想要的非常朴素,既要简单的分析过程,也要简便的校验,快速地进入分析系统里对过程进行核查。 因此,我们一直在围绕客户痛点和客户的需求去迭代我们的产品。
帆软产品结合大模型的
发展方向
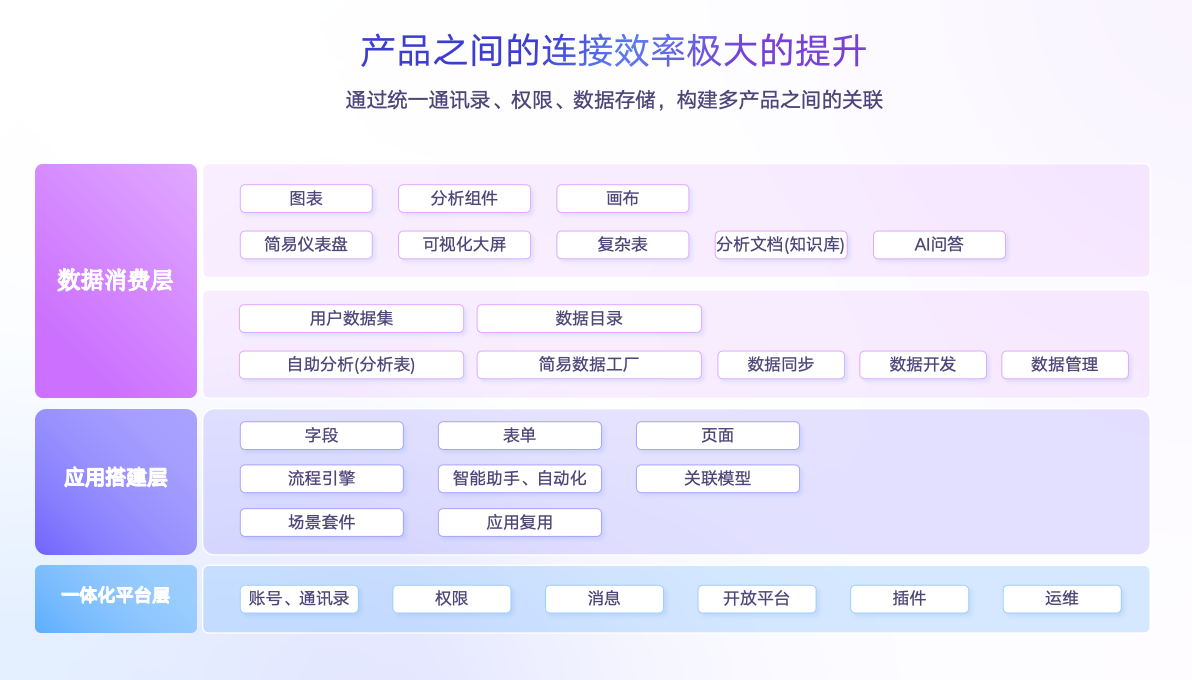
原来帆软的产品策略是在某一个领域去发挥自己最大的能力,把某一个场景做到极致,所以我们各个产品都是相对比较独立的。我们有简道云,有BI,把简道云的数据要拿到BI来做分析,是存在一定麻烦的,需要做数据同步,权限也没有打通。但是在AI时代,我们希望数据能够极大地被利用起来,所以我们构建了一个统一的平台,让帆软的所有产品都接入这个平台,这个平台上统一了账号信息、通讯录、权限,以及再下层统一了数据存储层。A产品生成的数据可以在B产品里快捷地调用。通过这样的方式,我们可以把这些数据充分利用起来,让大模型发挥更大的威力。
接下来列举几个场景,来介绍一下帆软产品如何结合大模型去应用。
1、借助大模型检索已有数据资产
在AI还未出现之前,企业已经沉淀了很多数据资产,比如说门户里挂了很多看板,这些看板数据通常都是经过了IT或者业务人员的检验,是一个可信的数据。但是要去看这个数据比较麻烦,不管是要打开系统进入到看板页面,或是去问别人,让别人打开来看,都要花费很多时间。
比如我正在去机场的路上,想看一下当天有哪些同事的业绩有异常。我虽然知道有这个看板和数据,但我要一个一个在手机上去找,甚至我要多打开几个模板的话,要来回切换,会花费很大精力。
我们通过对已有数据资产的整理检索,检索完了以后,让大模型把检索出来的结果进行重塑,再返回结果。比如提出问题:到目前为止我们有哪些战区的回款还没有达标?把没有达标战区负责人的名字给我列出来。如果直接去基础数据找是找不到的,因为原表没有做这样的分析,通过看板数据的检索,检索出来这些数据发现北京、上海没有完成,不用打开看板,直接通过自然语言对话就能达到目的。因此,通过AI把我们原来积累的数据资产更好地利用起来,这就是帆软目前做的一个非常垂直的场景,我们希望这个场景能够最大化让沉淀的数据资产被很好的利用。
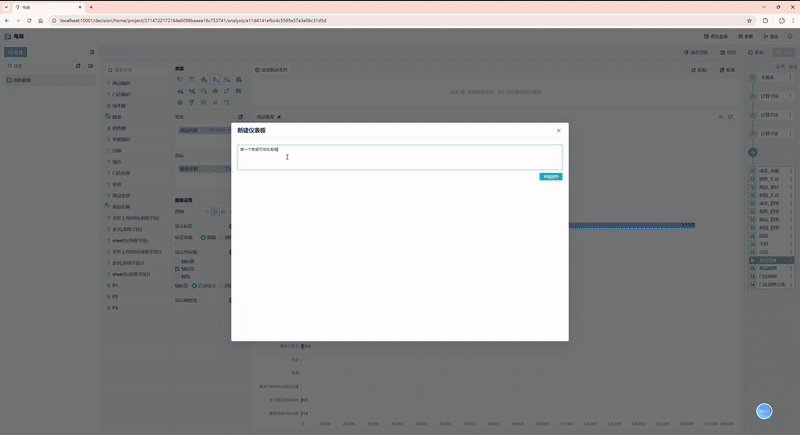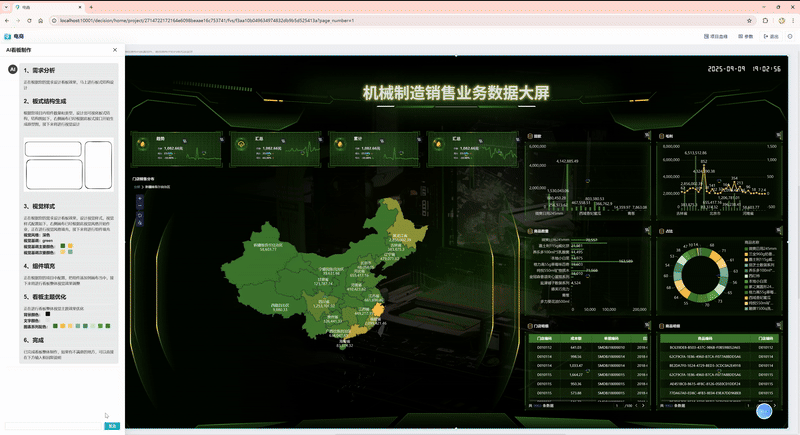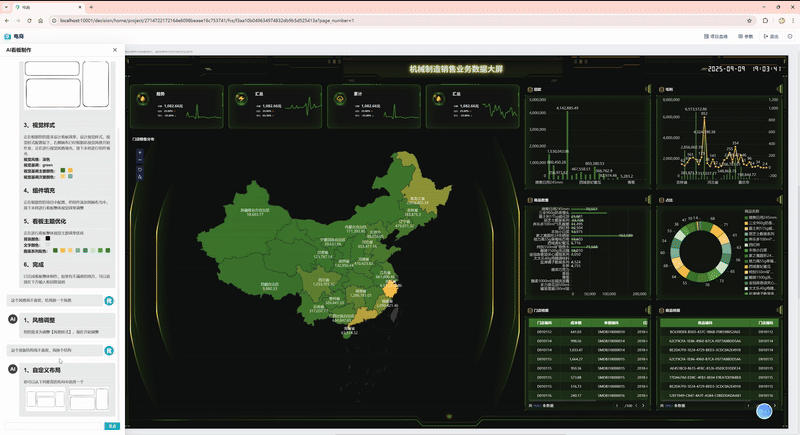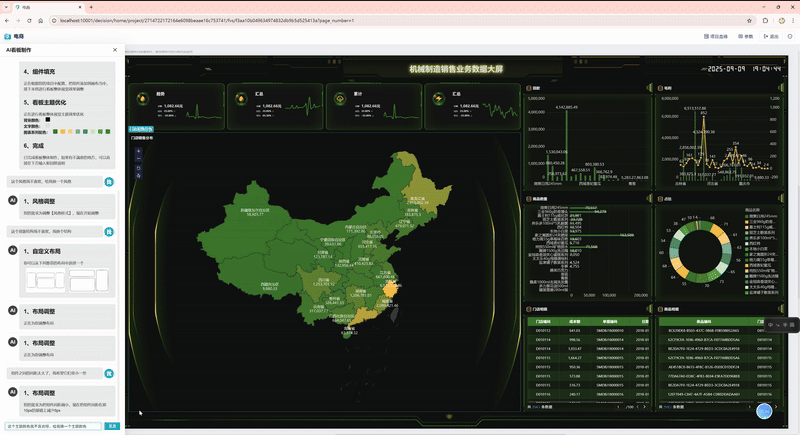
2、借助大模型简化仪表板制作
第二个场景是借助大模型简化仪表板制作。大家知道做看板的时候有一个很痛苦的问题,就是想做好看一些要花很多时间去找素材、调整布局等等,要花费很多时间。
帆软在历史积累当中,沉淀了数十万个不同风格的模版,什么风格受到很多人喜欢,哪些风格不太行,我们利用这些已经沉淀的数据进行标注,再结合大模型训练,训练之后的大模型可以快速生成相对美观的看板,只需要进行一些微调,就能做到你满意的样子。这种方式把几个小时甚至几天的工作缩短到几分钟、十几分钟,极大降低了对人力的消耗。
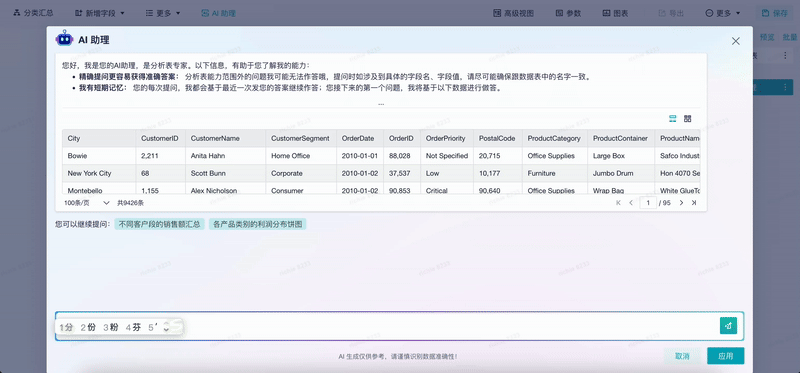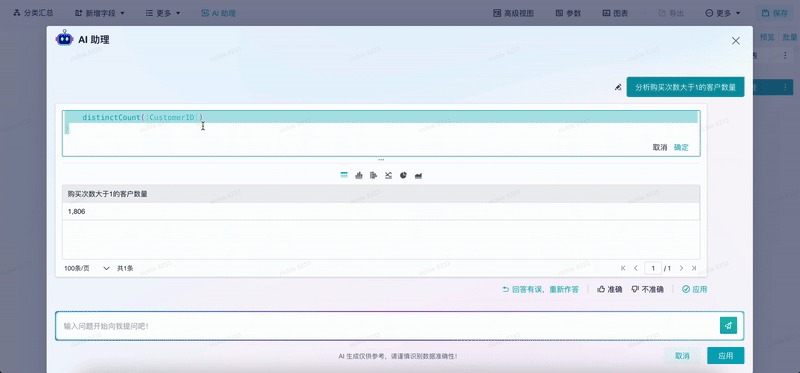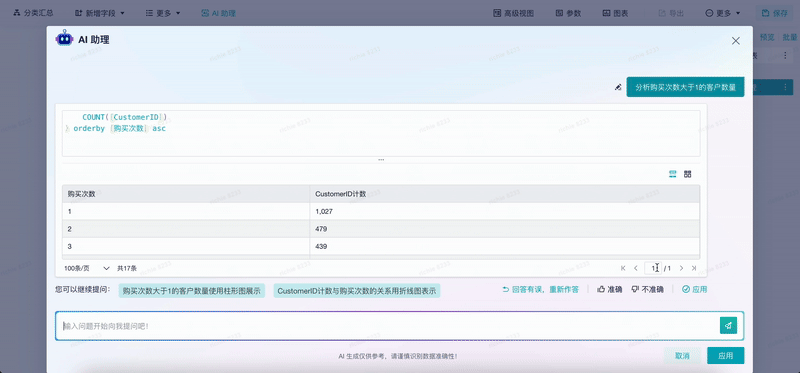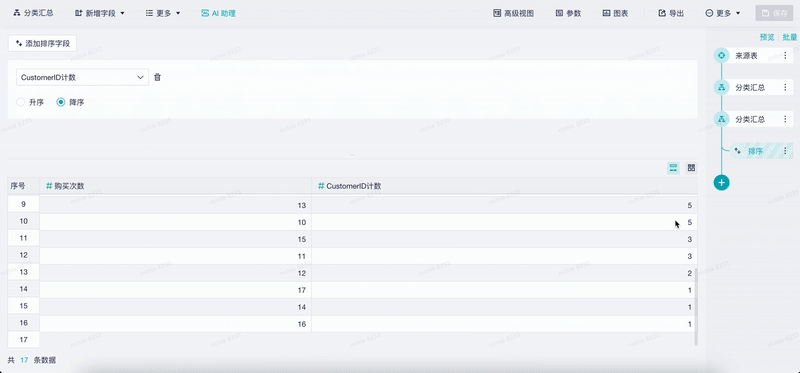
3、既高效、又支持随时核查的AI助手
第三个场景是既高效、又支持随时核查的AI助手。结合刚才的用户诉求,用户需要的是既要能够快速去做分析,也能够快速地去校验分析的过程,所以投入了相当大的精力来满足用户的诉求。
我们看这个视频,用户通过自然语言去生成了一个相应的分析结果,这个分析结果可能比较复杂,演示的内容相对简单。第一步是把大模型生成自然语言在我们的工具里可以被应用,输出结果,二是把生成分析结果的过程转成原来分析工具中的可视化步骤,有了这个步骤,用户可以根据需要去调整,AI就能够辅助用户去做分析,而不是替代用户去分析。“辅助”还是“替代”这两者的差距就在于最后谁对这个结果负责,显然人才是要对这个结果负责的。
通过这种方式,我们可以做到既让用户低成本使用我们的分析工具,也能让他们快捷地去查看分析结果的可靠性。
可信数据分析方案
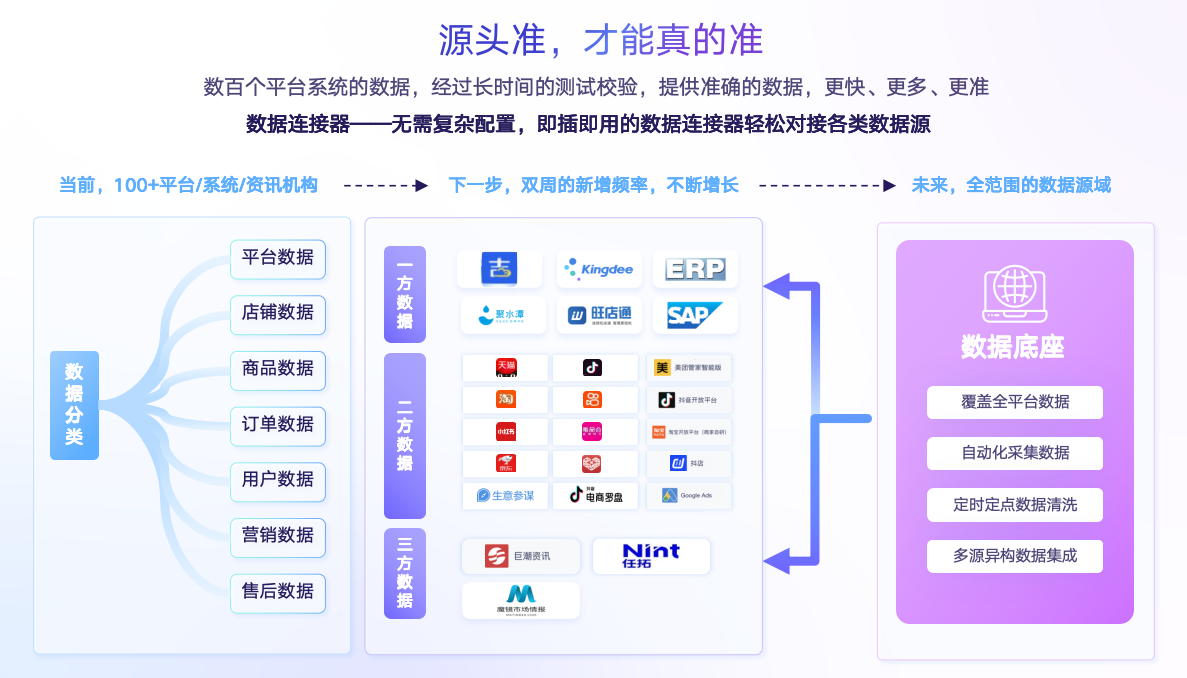
前面讲了数据不准确是非常令人头疼的,我们公司内部也有这样的例子,商务跟销售战区代表说,你的合同跟开票数据对不上,什么原因?不知道,排查之后发现原来有一个数据是通过别的系统录入的,没有走统一的入口,流程不规范导致源头数据不准确。面对数据不准确问题,更多时候只能靠人工去核查排查问题,我们认为源头准才能真的准,源头数据是否准确,决定了接下来的分析过程以及最终的结果能否给出准确的信息,而准确的结果才能帮助我们的业务。我们经过大量人力投入,接入了数百个第三方的应用平台,几千张表的数据,这些数据经过了我们跟早期客户共创试,保障数据准确性,这些准确数据才能更好地帮我们做决策,做应用。
同时,应用体验方面,原来我们可能要写一些代码才能引入第三方平台数据,现在只需要花费几分钟时间,在界面上简单配置就可以完成第三方数据的引入了。与此同时,帆软还有一个应用复用团队,产出了相当多高价值应用模版,这些应用只需要替换第三方数据源,就可以快速被应用。
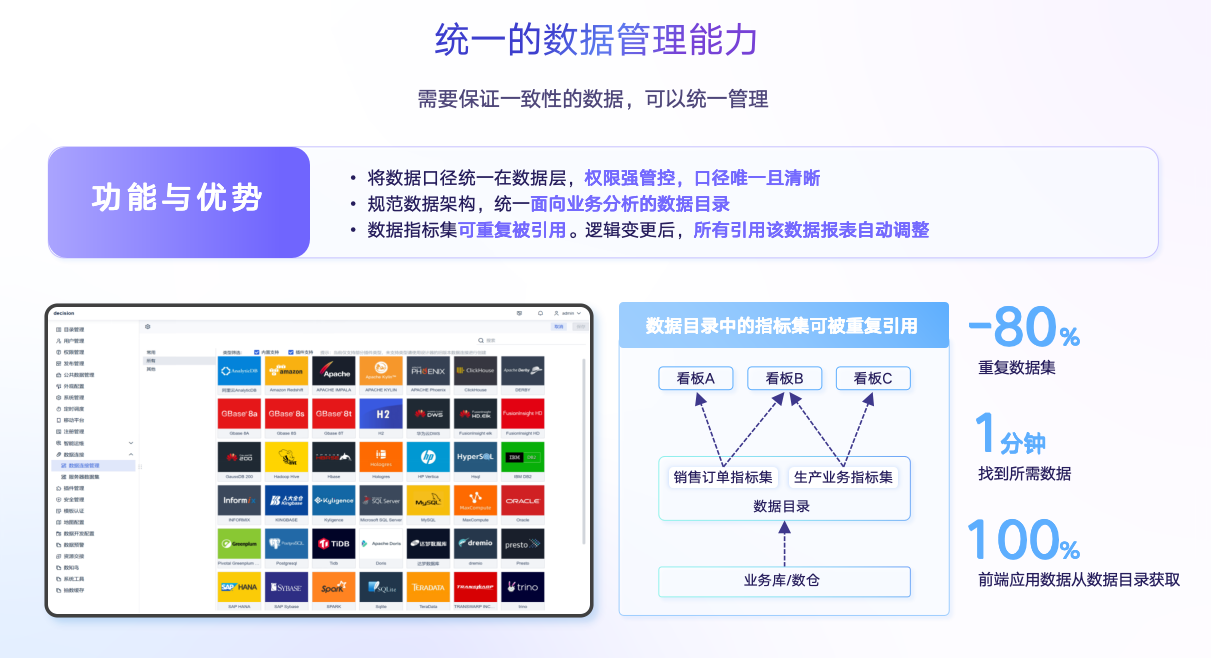
另外,要保证数据的准确,还要有能够统一定义数据的地方,因此我们也提供统一的数据管理能力。原来自助分析比较流行,很多业务部门要各自做分析,这样带来的后果是每个业务部门有自己分析的口径,导致数据口径不统一。因此,我们在新的版本里面提供了对统一数据的管理方案——指标平台。
通过指标平台,可以把所有共用的这些指标统一管理起来,让所有使用这些数据口径的地方是准确无误的,这些口径都是IT和业务共同校验过的,他们作为数据的持有者要保证数据的可靠性和准确性。原来做分析的时候要做很多表实现计算结果,有了这个指标平台,可以减少60-80%的中间过程计算,减少了这些中间表,就减少了维护系统的负担,能够更好的让系统运转起来。
最后,我们保证了数据源头准确、口径一致,但是我们还是对分析的数据有怀疑,如何快速去排查出错的数据在什么地方?可追踪的数据源头是我们认为让数据可信的一个根本性措施,因为没有人能不犯错,也没有工具在人的使用下能不犯错。犯错了,我们能快速纠正错误才是解决之道。
帆软提供了全链路的血源管理,不管你在哪发现了错误,我们可以快速追踪到数据的来源,是哪个指标可能出错了,还是哪个数据处理可能出错了,甚至在哪个数据的源头也就是数据库里面出来的时候就出错了,直接在血缘关系上就能排查。通过这种方式,我们可以降低犯错之后对这个错误的排查和定位的消耗。
以上几个措施就是我们在AI时代如何保证数据分析产品的一些可信性的方案,当然,光有了工具还不够,因为工具是需要有熟练的人、熟练的组织去使用,才能更好发挥工具的作用。因此,帆软的数据应用研究院就是为了解决这个痛点,我们推出了《企业数智应用白皮书》,它提供了数智趋势的洞察,标杆企业的数智应用实践,协助企业了解当前的趋势。同时,我们还发布了《企业数智人才的建设地图》,里面展示了建设企业数智人才全生命周期的方法论,有了人才才能把企业数字化转型更快推动起来。
最后,帆软的工具、人才服务能够帮助企业在数智化转型的道路上越走越远,谢谢大家! |