|
序章 不定期的被动运维
“陈工,我们对SPC预警已经处理过了,但是生产的监控大屏中SPC预警仍然存在。”
这是一年前,我经常接到的电话。每当监控大屏出现预警,值班人员因不熟悉预警逻辑,只能紧急联系我。从接到电话、排查问题、联系业务部门到最终验证恢复,流程冗长。大屏数据与生产操作是紧密关联的,一旦数据不对,运维问题就会频繁发生。同类问题反复发生导致运维单反复提交,陷入“报警-救火-再报警”的循环。
这个大屏仅仅是SPC运维过程中很小的一部分。长此以往,整个运维过程效率低,服务质量不高,部门运维工作将处于被动的局面。经过近一年的主动治理,我们已成功将SPC软件运维模式从“被动防守”转为“主动运维”。成效显著:同类型高频预警引发的运维工单减少80%以上,运维人员独立处理时长从1小时以上缩短至10分钟内,整个团队运维效率与服务质量明显提高。
总结下来,我们系统性地开展了以下工作:
经验转化:我将SPC软件相关的运维问题、典型场景排查步骤固化为标准化文档,放入运维知识库。并通过周例会,确保每位值班人员都能快速理解与应用,通过与SPC的核心用户交流,让大家都能进行基本的问题查询,减少频繁报警的可能性。
源头根治:对高频告警进行根因追溯,特别是重复发生的问题,进行单项跟踪。联系厂家处理,和开发人员一起协调解决,从源头上减少咨询类问题、数据交互问题80%以上,推动运维向标准化、主动化转型,跳出被动低效的循环。
流程提效:对SPC运维问题,通过流程化、信息化手段,对关键性问题复盘、闭环。同时,也形成了结构化、可处理、可分析的运维工单数据,大幅降低对不同运维人员个人经验的依赖,提升服务质量和团队运维效率。
如今,当值班同事再收到“SPC预警仍存在”的反馈时,已能从容定位问题,90%的运维工单都可独立闭环。团队彻底摆脱对单一个体的依赖,摆脱对源程序的依赖。很长一段时间,我们看到的是一个没有预警的预警大屏。

第一章 运维难点
SPC软件本身,数据库表数据量根据实际业务,会有很明显的波动,数据库运行一直正常。但是,有一次收到SPC超时报警运维单。当时由于时间紧急,直接联系厂家,排查出SPC数据库一张业务表数据量过大导致。运维问题是解决了,但是处理过程耗时久,对生产造成一定的影响,这种问题必须想办法杜绝。
另外,我们运维的信息化系统很多,就SPC软件而言,已经和多个业务系统对接。所以运维问题不仅仅体现在软件本身的使用上,还可能在其他交互系统的业务逻辑上。很多咨询类的运维问题,比如在SPC中查看不到异常数据,大部分都是对接的系统没有传递数据导致的,由于SPC系统没有任何记录,也就无从查起。
经历过一个个活生生的案例,整个运维团队都有一个共同的想法,如何让我们的运维工作不再被动防守?特别是对于那些重复发生的,容易发现根因的运维单,我们应该采取一些可行的措施,变被动为主动。
第二章 问题分析
带着运维值班遇到的SPC模块的问题,我积极采取措施。对于软件本身的问题,要对业务部门定期培训,指导如何查询基本的数据逻辑。至少,在SPC运维过程中,不再频繁收到咨询类的运维问题;对于对接系统没有传值的问题,只能我们自己查询为什么SPC没有接受到数据,可能是业务逻辑没有定义,也可能是接收到了,但是数据造成异常;对于大屏数据和SPC数据不一致,自己主动去发现问题,而不是等到业务部门打电话,自己再被动的去处理。
但是,这种处理方式,是有局限性的,针对某个具体问题,进行具体分析,找到解决办法。对整个部门而言,其他的业务系统运维怎么做?尤其是资源就这么多,如果所有精力都花在运维上,部门其他的工作就没法开展了。
大家都希望找到一款数据清洗与分析的工具,对我们的运维工作进行系统性的分析,看看我们的信息化系统运行情况、服务生产的情况,从而主动的预防故障、提升运维效率,让我们部门降本增效。
第三章 主动出击
之前,我使用过帆软的产品。于是,我试着通过FineBI对我们的运维数据进行分析。由于工作分工的原因,下面只涉及SPC软件运维内容。
1、 我们处理的快不快?
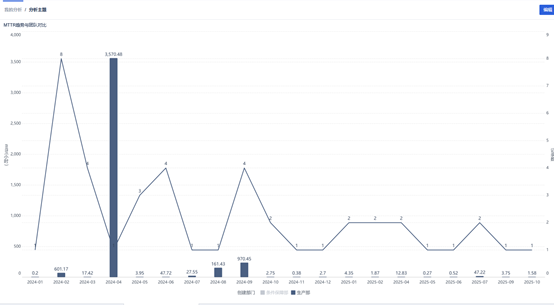
通过组合图,分析我们处理运维问题的速度。MTTR平均解决时间,从开始处理到关闭的时间,这是核心的效率指标。通过该指标分析我们运维值班的运维效率,响应是否及时。MTTR是逐月上升还是下降,识别效率拐点,不同团队、不同分类的MTTR对比,找出“效率洼地”。
从图中不难看出2024-02、2024-06、2024-09,有一个明显的波动,需要进一步分析。经过分析实际数据,我们的响应时间是非常及时的,不会有图中970.45小时这样的数据。图表中的计算公式用的是运维问题提交时间到问题解决的时间,后续需要将MTTR分解为“提交时间”、“响应时间”(开始处理)、“等待时间”(如等待厂家处理)、“完成时间”等。通过拆解聚焦耗时最长的环节,分析工程师个人/团队的吞吐量(单位时间处理工单数)及复杂工单占比,用于平衡工作量与能力评估。
2、 问题出在哪?
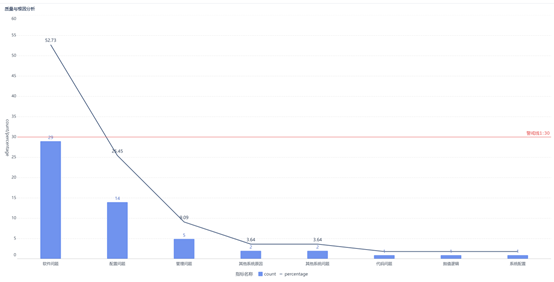
通过组合图,分析质量与根本原因。从图中很容易发现主要原因:软件问题、配置问题、管理问题,其中软件问题最为严重。按照帕累托图(二八法则)展示,导致80%工单的20%主要原因,定位TOP故障源,也是集中在以上问题。当然,后续要结合业务实际,对问题分类更加的明确、细化。
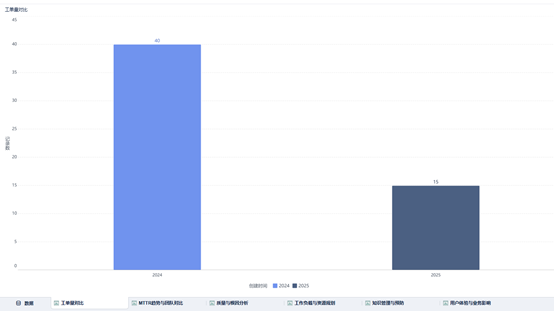
3、 我们工作量有多大?
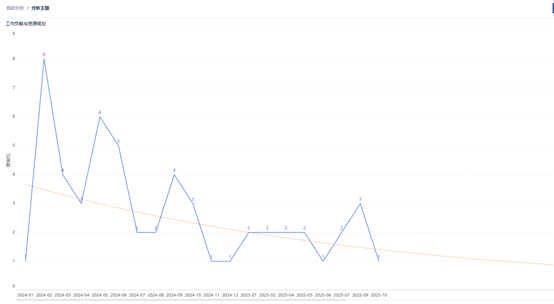
通过折线图,分析我们的工作负载。过滤掉简单咨询类工单,通过历史数据进行预测,可以发现我们的SPC运维工作量呈下降趋势。进一步,我们还可以从时间维度,进行工作日/周末,白班/夜班等数据分析。发现业务的变化趋势,预测未来一周、未来一个月的工单量,用于人员、资源的预安排。
4、 能否不重复解决同样的问题?

通过词云,分析我们SPC运维中的重复问题,做到知识管理与预防。通过识别问题描述相似、根因相同的工单,达到创建知识库或实施永久性修复的目标。图中出现较多的包括:其他系统导致的问题、关系配置问题、对于频繁发生的告警类、咨询类工单,通过培训、完善操作流程、改进产品来从源头减少运维问题。
5、 问题对用户和业务影响有多大?
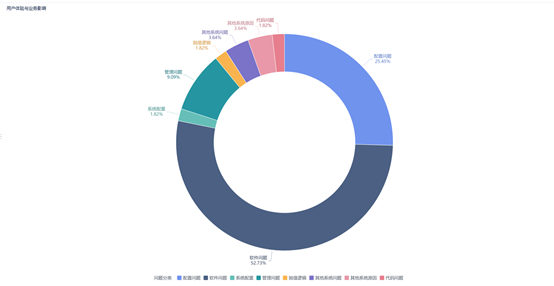
通过饼图,分析用户体验与业务影响。结合工单的“影响范围”,分析哪些问题占比多(例如图中的软件问题),是使用问题还是系统本身不稳定(例如图中的配置问题、系统配置),该问题影响范围是个人级、部门级、公司级,该问题紧急程度等。对于重点工单(例如图中的管理问题),进行专项复盘、跨部门沟通,尽快处理。
经过整个运维团队的努力,我们已经取得了一定的成绩。对比2024年,今年仅SPC运维工单量,就减少了62.5%。
以前,我们接到运维值班电话,更多的回复是等我们处理完;现在我们接到电话的第一时间,就告知业务部门问题是什么,以及处理的办法。记得有一次我运维值班,业务部门打电话之前,我已经把问题处理完了。针对SPC的预警大屏,业务部门不仅增加了其他的逻辑,而且遇到问题,已经知道如何自行处理。
第四章 运维总结
很多人说软件运维比软件开发容易。但是我不这样认为,不论是甲方运维还是乙方运维,都有很多工作要做。尤其是当下,业务部门都不再满足问题现状,从管理层到生产一线,都希望主动发现问题,从而提高解决问题的准确性、及时性。
FineBI带给我最大的改变,首先是学会了一项数据分析的技能,然后是建立了一套数据采集、数据清洗、数据分析的模型。可以说FineBI改变了我的运维观:
还记得之前使用FR的时候,我们没有搭建流程。自己通过表单填报,一样实现数据的原始收集。例如,软件运维工单的数据,通过FR表单填报就能实现数据采集。
数据清洗需要对我们分析的维度、事实进行科学的归纳、总结,找出我们需要的数据。例如,日期字段怎么用,聚合函数怎么用,重复数据怎么处理,空数据是否需要过滤等,都是摆在我们面前且必须面对的问题。
运维工单的数据分析应从效率、质量、数量、知识、价值五个方面展开。每一个运维工单,不能孤立的对待,运维团队也要多提问,多反馈,从整体上解决根本性问题,提高运维效率,变被动为主动,最终实现数据的高质量价值。 | 

