概述
目的
本文档主要描述帆软的开发管理规范。运用本规范管理帆软开发的全过程,可以保证页面展示的一致性,使整个过程设计更科学、实施更快捷、维护更简便。
适用范围
本规范适用于各业务域和BI项目的帆软开发设计,适用角色如下:
帆软开发人员;
帆软运维人员;
帆软报表分权管理员;
数据仓库模型开发人员(指对接帆软展现的模型层设计和开发者)。
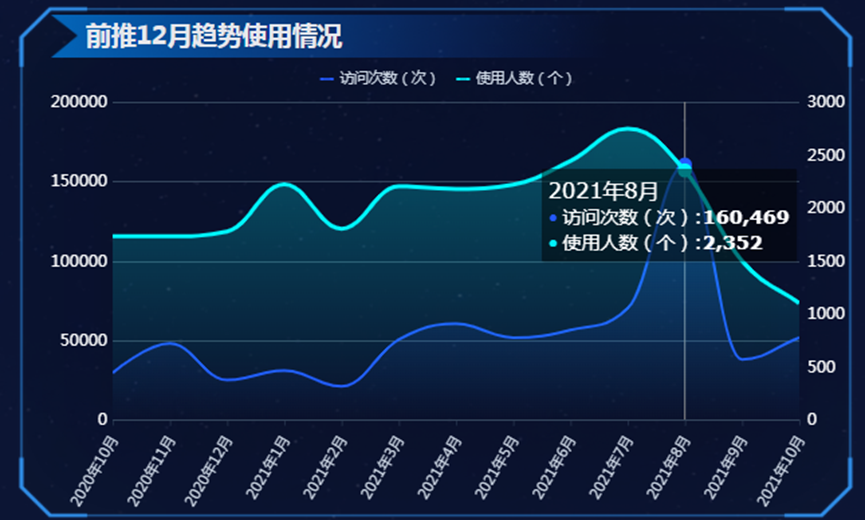
帆软报表开发及上架流程
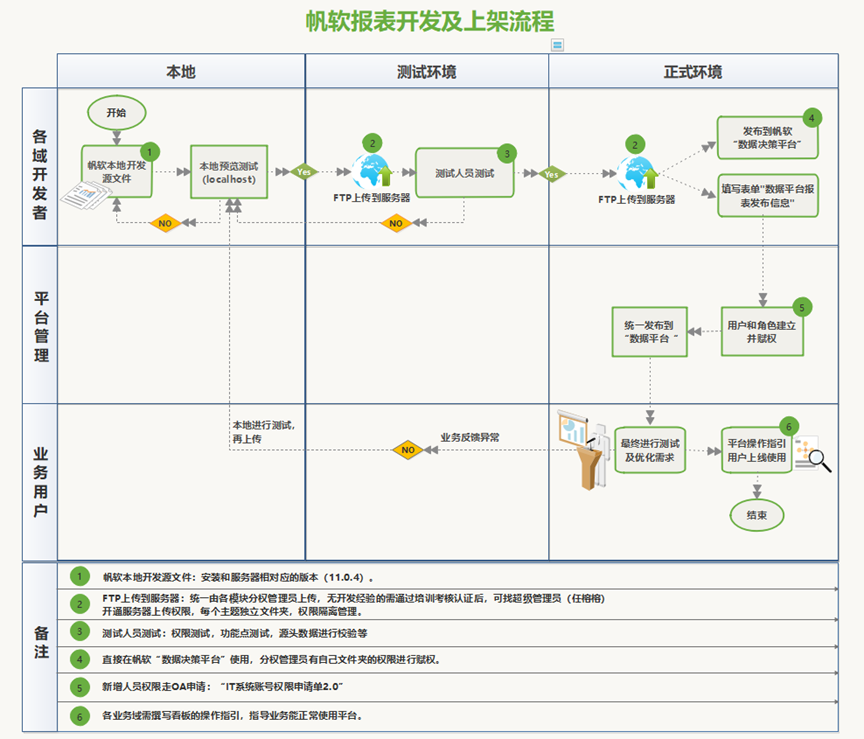
注:开发需严格按照“帆软报表开发及上架流程”进行操作,不能把正式机当成测试机进行测试,目前测试和正式环境功能点和版本都是一致的,需本地上传到测试机进行测试确认后,再发布到正式机使用。
性能要求
领导视窗决策看板查询时间不能超过5秒,普通报表查询时间不能超过8秒,明细报表特殊场景查询时间不能超过15秒。
统一SQL执行要求:SQL执行时间不能超过5秒,5秒以上的会被检测到并进行优化。
领导视窗决策看板SQL执行时间不能超过2秒,普通报表SQL执行时间不能超过3秒,明细报表特殊场景报表SQL执行时间不得超过8秒。
帆软开发管理规范
下文中,以“帆软设计器”指代“帆软本地安装的客户端”,“Server” 指代“帆软 Server”,“数据源”指代“帆软数据源”。
数据源
1)针对页面展示或数据分析无意义的冗余数据,如5年前的数据,优先在后台层面过滤掉;
2)后台表/视图需按照前端展现最细粒度汇总,使用帆软设计器只需连接到展现分析的字段数据(如前端展现最细粒度为督导时,结果集/后台视图/表细到订单行号是不合适的);
3)前端所连接的每一个后台表/视图查询时间都不应超过1s。若后台表/视图本身查询时间较长,需先从后台层面做落地或优化:
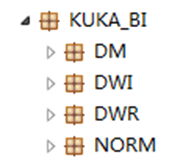
4)如无必要,模板数据集不要有过多表/试图的关联,如需要多表/试图关联,请在模型里处理好对应逻辑,报表直接引用最终模型DM层来展现结果。
5)如开发明细报表,帆软设计器老版本(11.0以下)转成CPTX(大数据集),11版本使用“报表引擎属性”下的“新报表引擎”。作用:默认只加载第一页,开发的时候设置界面上的导出功能(用JS写对应的导出)。可直接导出数据集,默认如下设置,把字段别名成中文,这样导出就和自带的导出表头名就一致了。写法:

(cpt模板转cptx格式:https://help.fanruan.com/finereport/doc-view-3550.html)
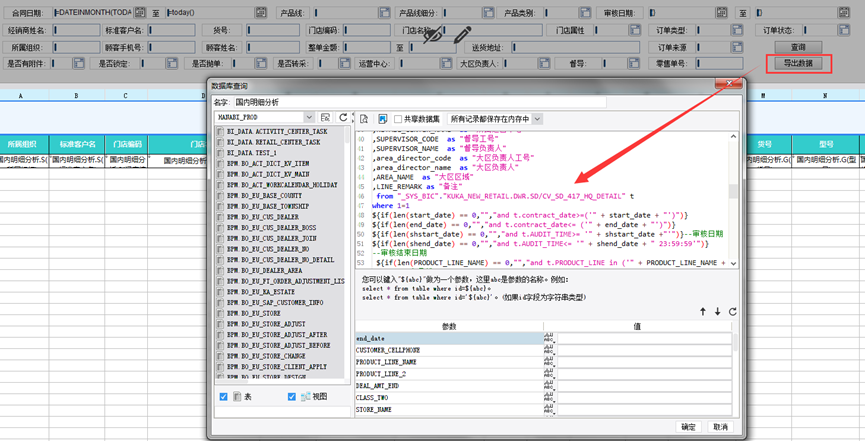
1. 模板限制如下:超出会报相关的限制错误;
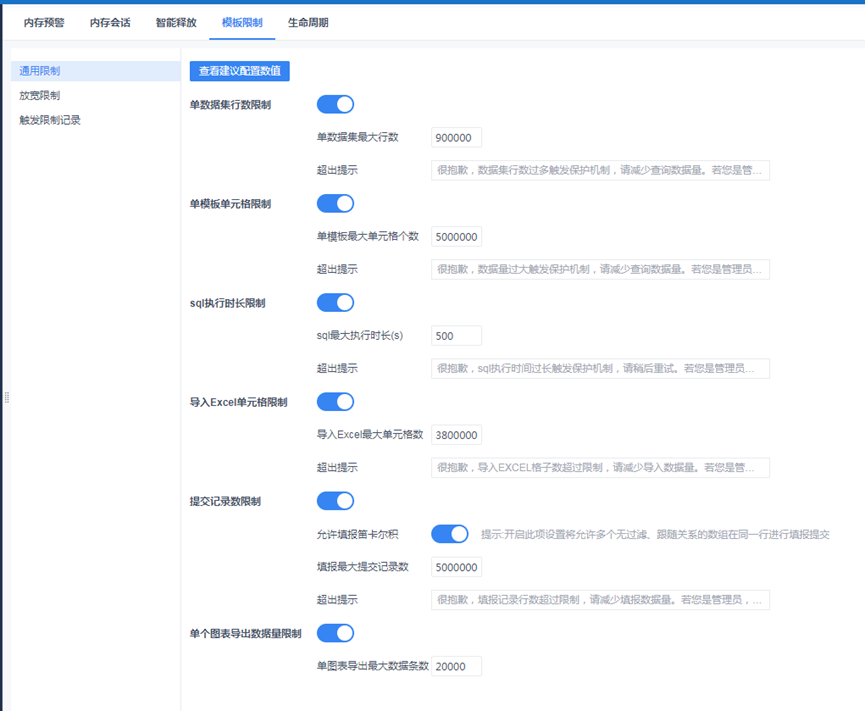
7)数据连接:本地的命名和服务器的数据连接命名要一致,区分大小写,如两边配置的名称不一致,查看报表会报错:“找不到数据连接:连接名”。

设计原则
1)同一仪表板包含模板数据集数量建议介于5到10之间(一个图一个结果,再加维度表多选需要设置数据集);
2)每一个界面的筛选器数量尽量控制在10个以内,如查看明细,可另做一张(前后两张参数名要一致,大小写区分),跳转出去查看。确保有效地使用每一个筛选器。
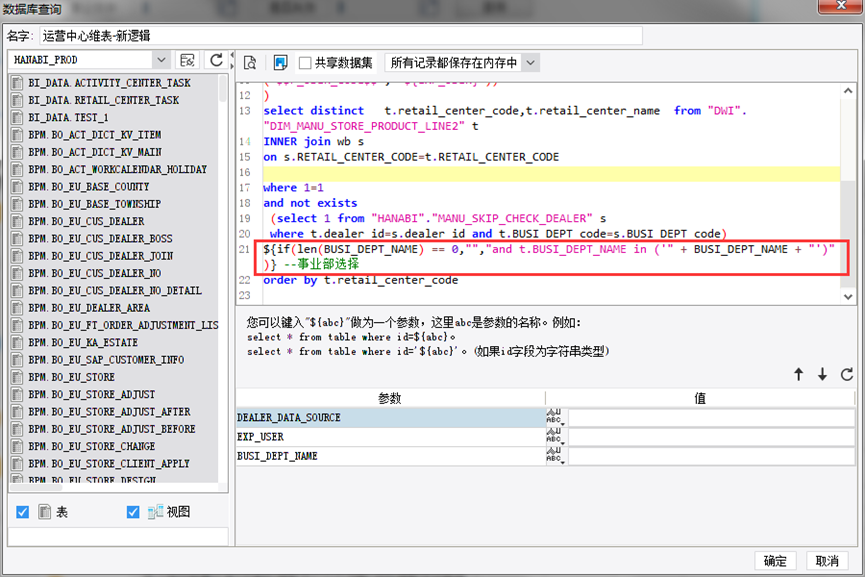
1. 如有上下关联,层级顺序需要优先级排好顺序:

4)下一级筛选器需加上前一级的参数(例举运营中心的维表写法),如图所示:
5)尽量减少类型转换函数的使用(可用相同类型写逻辑的情况不要来回转换类型);
界面内规范
基础设计
1)页面大小:根据显示的列设置
2)字体:统一用微软雅黑,标题字号18,需要加粗,颜色默认为ffffff。
3)参数面板:通过代码传参,显示名称,字体微软雅黑,字体大小9(默认)
4)单模板最大单元格个数:300000
5)标题和表格前面的文字段落之间留有一厘米的间距。
6)显示筛选参数值:时间+口径等等重要参数;编制单位:字体大小10,颜色为ffffff,靠左对齐;
表格:
1)、表头需要加粗,背景填充色号为33cccc,字体大小10,颜色为白色,居中对齐;
2)、表头行高10mm,表内容行高6mm;
3)、对齐方式:数值(如数字、百分比等)靠右对齐,其他居中对齐;
4)、表格边框颜色:c0c0c0;
5)、表内容字体大小10;
6)、数值默认保留2位小数(整数无需小数点);
7)、合计行字体加粗;
维度字段数据设置默认为合并;
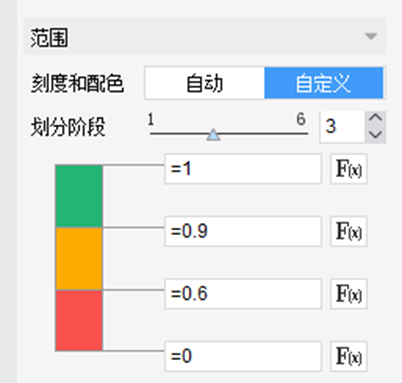
预警颜色使用红(ff344d)、橙(ff9900)、黄(f2f20a)、绿(7ed321)。
图表:
图表需要显示标题,标题字体加粗,字体大小16,位于图形上方,居中显示;
图例位于上方
参数命名规则
1)不能以数字、$ 符号开头。
2)变量名只能是字母 (a-z A-Z)、数字 (0-9)、下划线(_)、(@) 或中文的组合,并且之间不能包含空格。
3)变量名中不能含有 ? * . - 等字符和空格。
4)变量名不能使用编程语言的保留字。比如小写的 true、false 等保留字。但大写的 TRUE、FALSE 可以。
5)帆软自带参数:跟帆软一致
6)模型参数:跟模型一致
7)自定义参数:字段名称,如SALES_ID,
8)有时间范围的参数加上START,END标识:START_DATE,END_DATE
9)SQL最大执行时长:60s,普通一段SQL不能超过5秒,如超出会被监控到反馈优化调整。
10)单数据集最大行数:300000
注意事项:统一规则:使用大写的英文来传参,尽量不用到中文进行传参。
1)字符参数有英文单引号 '${ABC}',数字参数没有英文单引号 ${ ABC }。其中 ABC为参数。
2)参数值的引用格式为参数前面加 $ 符号,如$ ABC。
3)模板参数与全局参数重名时,采用模板参数。
数据集命名规则
1)、数据集命名:
· 维表:数据内容+维表,如:城市_维表;
· 业务数据:数据内容_作用区域,如:零售单数据_折线图
2)、数据集格式
· 代码行缩进统一用一个Tab键;
· Select中的字段分行排版,并且逗号在字段名前,注释调试的时候较方便;
· 字段名后面添加注释。
格式
1)工作簿字体默认微软雅黑,大小视整体设计而定,同一系列工作簿保持一致即可;
1. 字体颜色默认黑灰色,■RGB(85,85,85);
2. 仪表板背景色默认白色,□RGB(255,255,255);
3. 仪表板标题居中,同一工作簿中,其它标题位置全部居左或全部居中;
5)日期用于参数、筛选器或图表中时,采用简洁格式(YYYY/M/D);用于文字说明中时,采用完整格式(YYYY年M月D日);未跨年月份显示格式统一为阿拉伯数字+“月”的格式(M月):趋势显示可以-45度角来显示文字。
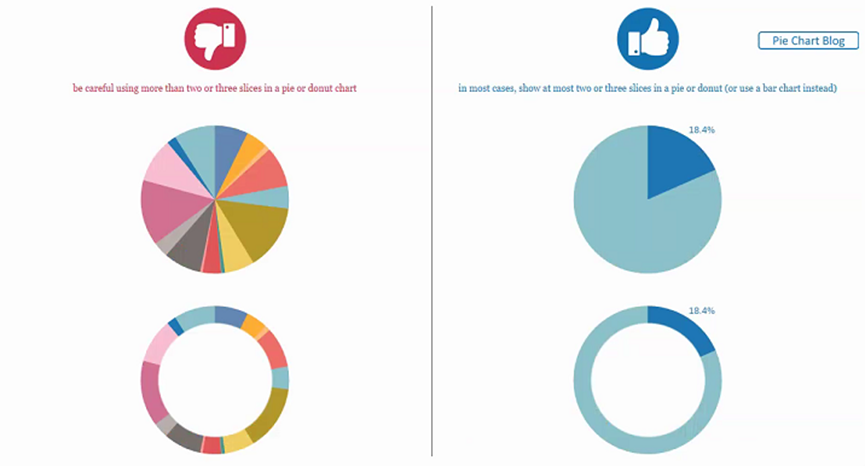
1. 在同页看板中,大范围的形状或颜色尽量不超过5种,避免因颜色滥用而分散用户注意力:
1. 图表中冗余的框、线尽量删除,或使用浅色代替:
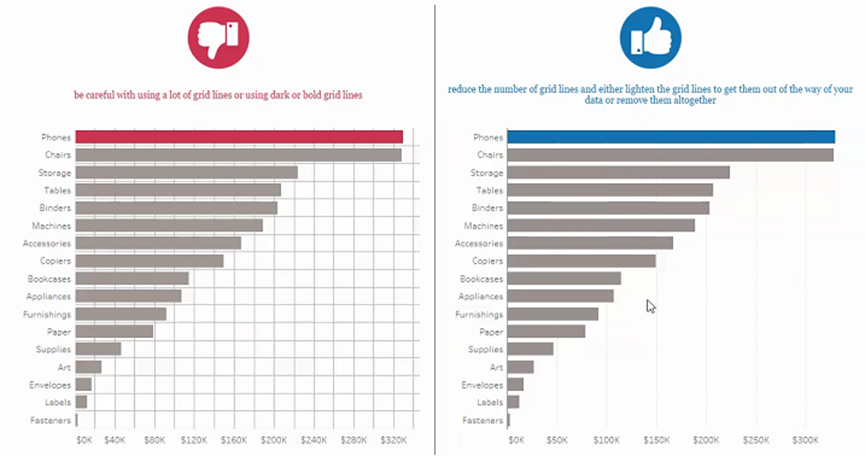
1. 工作表中已为每一个标记添加标签的情况下,删除无用的轴和刻度;
9)预警颜色与形状参考: RGB(248,81,75), RGB(248,81,75), RGB(255,170,0) RGB(255,170,0) RGB(34,181,115); RGB(34,181,115);
上升:  或 或  或 ▲ 或 ↑ ;下降: 或 ▲ 或 ↑ ;下降:  或 或  或 ▼或 ↓ ; 或 ▼或 ↓ ;
上传正式环境前
1. 先在测试机上检测能正常使用,SQL本地预览查询无异常;
2. 报表出现跳转的话,路径需和服务器上保持一致,不然点击会报“无法找到相对应的模板”;
3. CPT文件,直接查看最后页,看列有没有显示全;
4)如图表及大屏开发,调整设备分辨率,检查在最小或最大的极端情况下仪表板显示是否正常,是否出现多余的滚动条,需JS语句隐藏掉;
开发上线使用
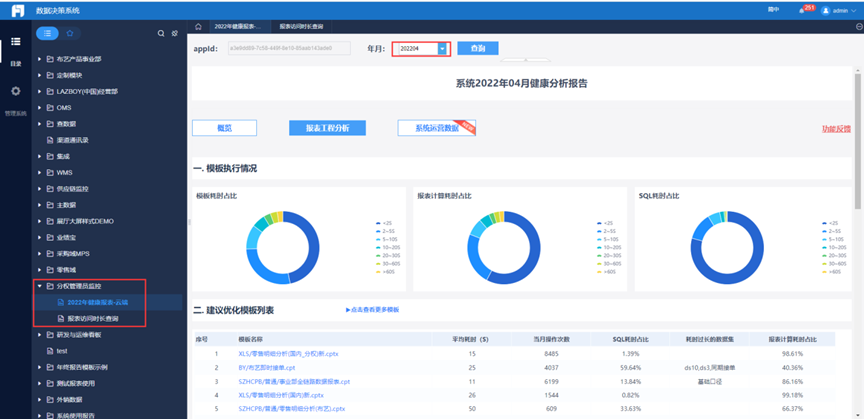
帆软自查性能的三种方法
页面初始化时长超过8s需进行优化后重新发布:
1)分权管理员:进入分权管理员监控——点击“2022年健康报表“;
可点击卡顿点查看哪些报表会被服务器记录监控下来,需要定期检查并优化。
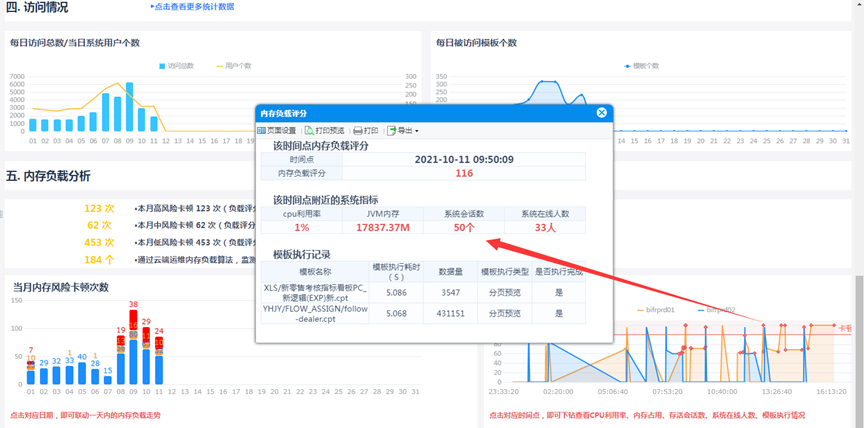
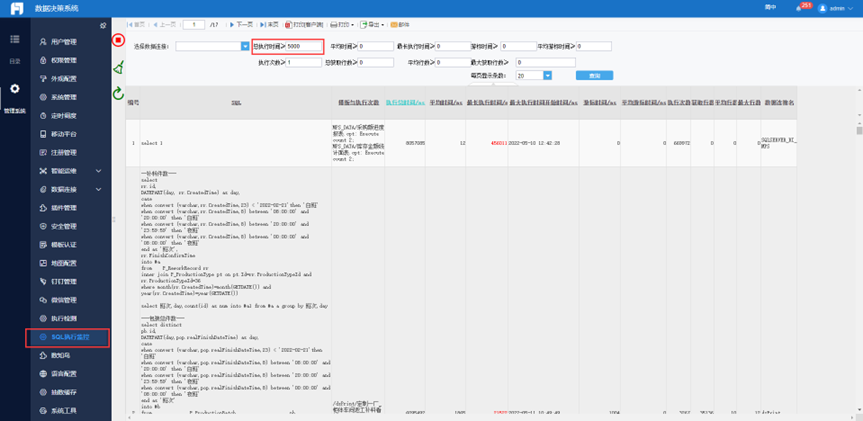
1. 进入“管理系统“——智能运维:
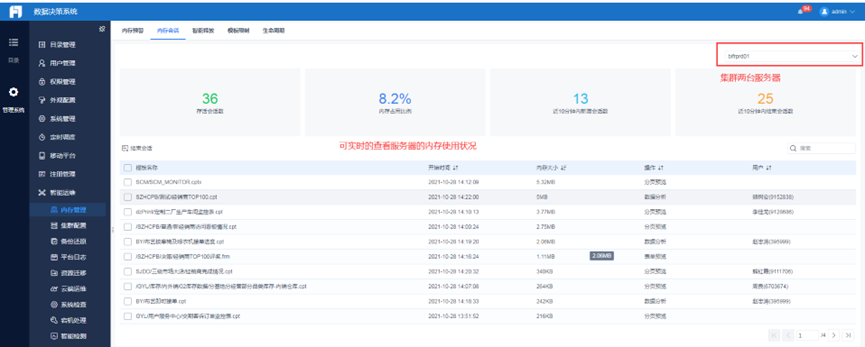
3)进入“管理系统“——SQL执行监控:
如无权限,系统管理员会定时发送到群里,自己认领并处理优化。
SQL超过5秒以上的都会进行通知调整,如多次提醒不调整的,会通知报表下架。
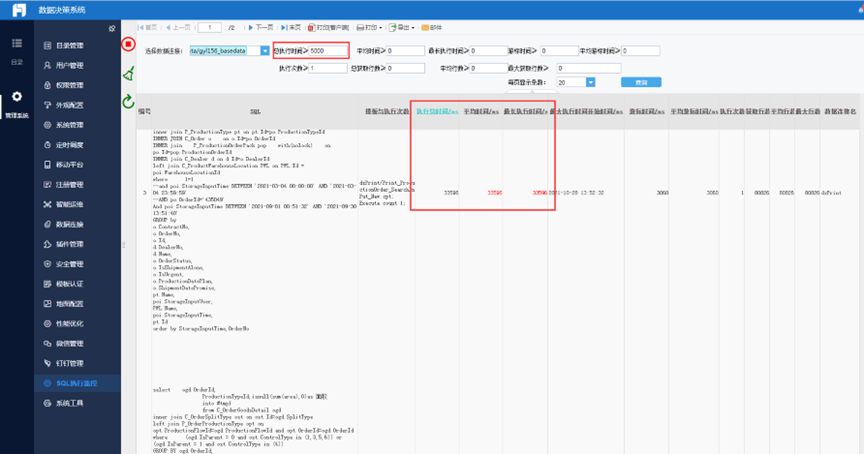
数据平台暂不开放管理员权限:
“发布至平台”以及相应的“数据权限和报表权限配置”,请联系流程信息化管理中心-数据分析组人员联系,并按要求登记《数据平台报表发布信息》。
填报还在数据决策平台里使用:
权限和顾家数据平台传参是有差异的,如需两边使用,需要单独开发。
开发参数及公式说明
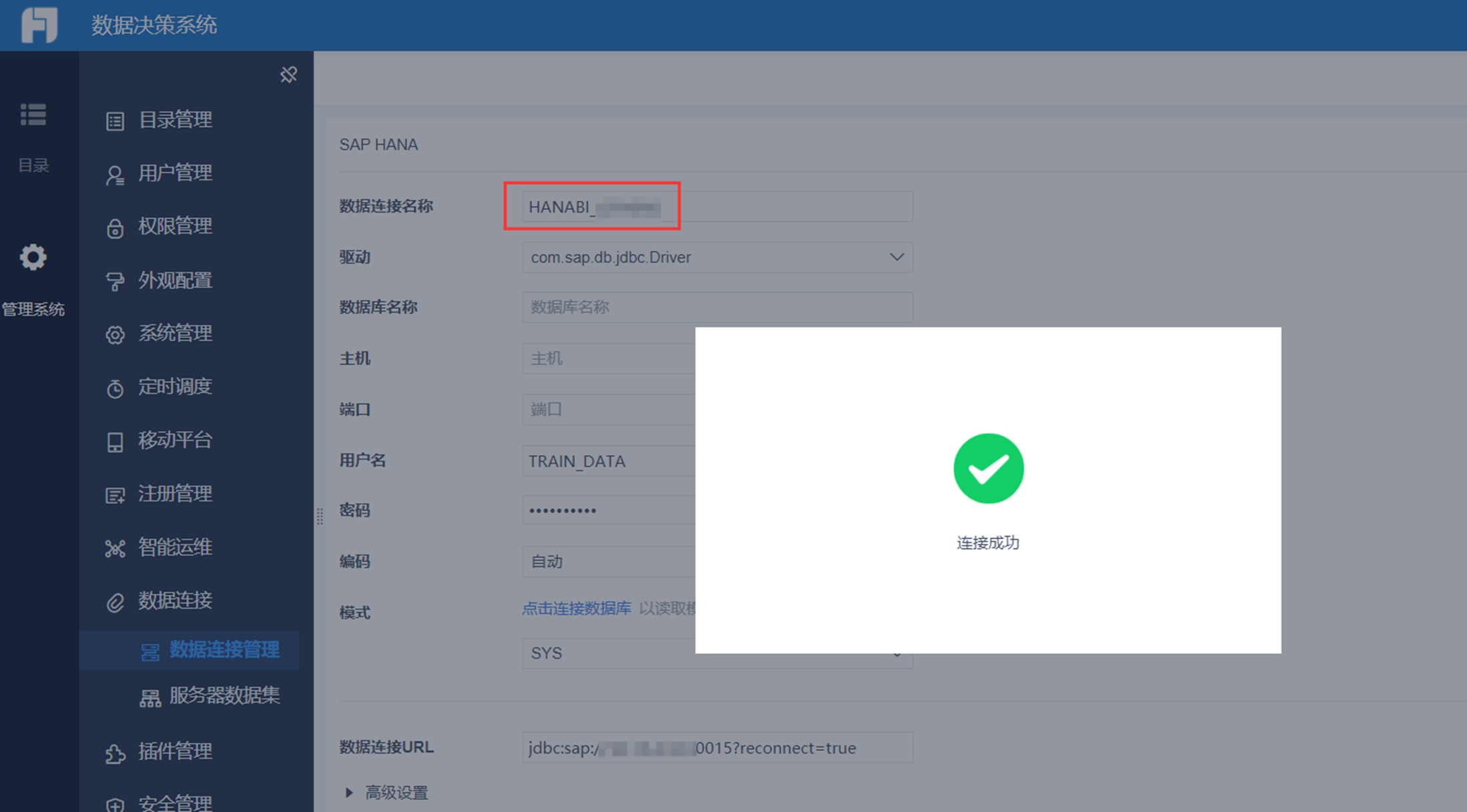
定义数据连接
注:服务器和本地配置,最终识别只按数据连接名称走,不同环境下数据连接名称里面的账号可以设置的不统一,可用来测试机和正式机的正常测试使用。
连接名称需统一规范标准:例:HANA数据库写法:HANABI_业务域,如命名不规范,要求修改连接名称,报表修改量会比较大,切记:在刚开始建立连接的时候就进行规范命名。
1) HANA数据库:
本地客户端配置:
点击“服务器”——“定义数据连接”
数据库选择Others
驱动器:com.sap.db.jdbc.Driver
URL: jdbc:sap://*.*.*.*:30015?reconnect=true
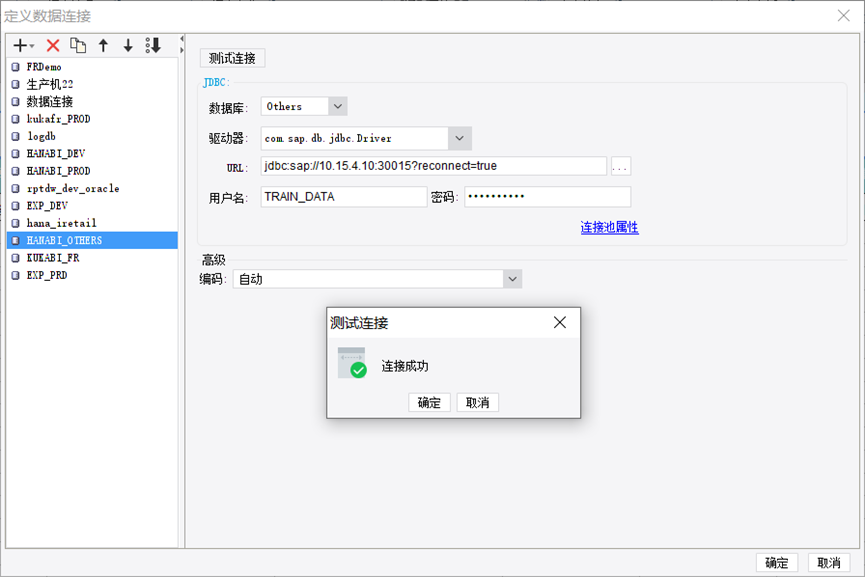
服务器上配置,找到SAP HANA进入配置相对应的,如是集群服务器,配置的时候链接:
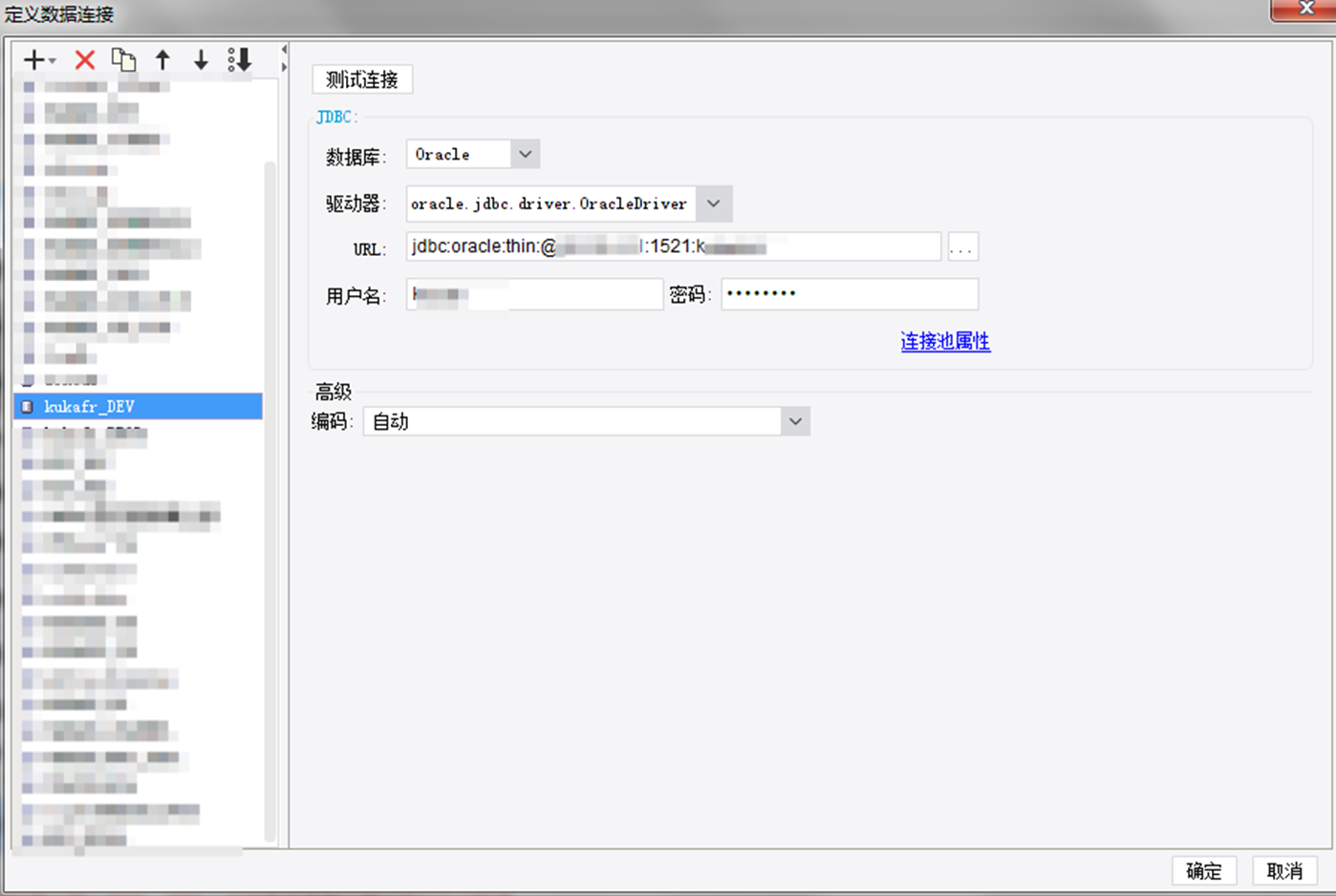
2) oracle数据库:
连接名称需统一规范标准:例:ORACLE数据库写法:ORACLE_业务域
本地客户端配置: 点击“服务器”——“定义数据连接”
数据库选择Others
驱动器:oracle.jdbc.driver.OracleDriver
URL: jdbc:oracle:thin:@*.*.*.*:1521:数据库名
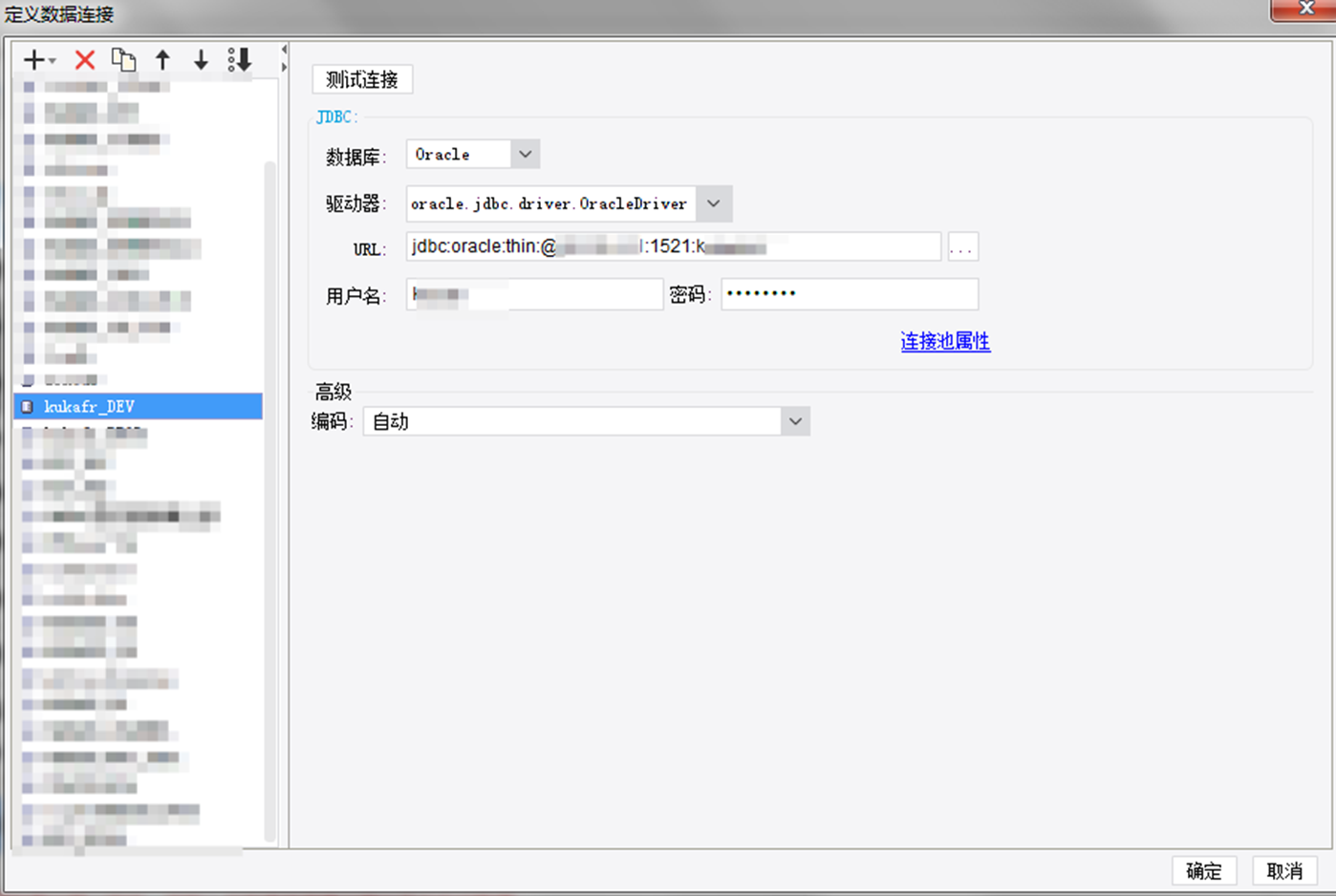
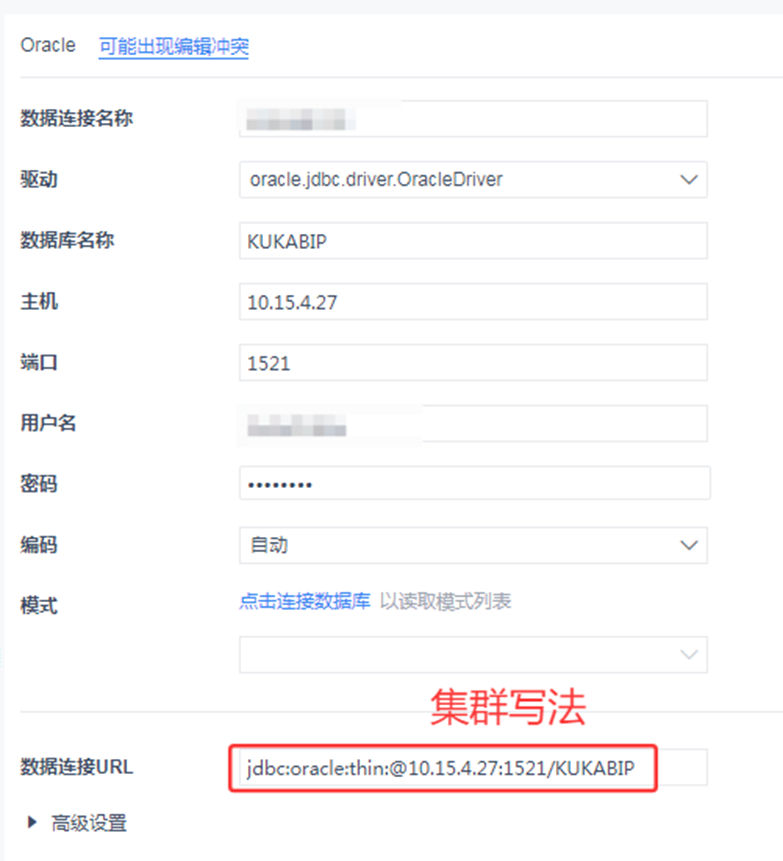
服务器上配置,找到SAP HANA进入配置相对应的,如是集群服务器,配置的时候链接:
需要把端口号后面的:修改成/
URL: jdbc:oracle:thin:@*.*.*.*:1521/数据库名
模板数据集/服务器数据集
模板数据集:只适用于当前报表。
使用场景:平常报表里面显示的字段内容都取模板数据集。
服务器数据集:是对应于整个报表工程的,更换模板或新建一个工作簿,都可以用服务器数据集中的数据。(注:目前服务器直连只有管理员可以,如需配置,可联系管理员)
使用场景:如维表选项参数都统一的情况下,可设置服务器数据集。
LINUX系统上传工具
用FTP上传,有些会出现中文乱码,需字符集“强制UTF-8”使用。
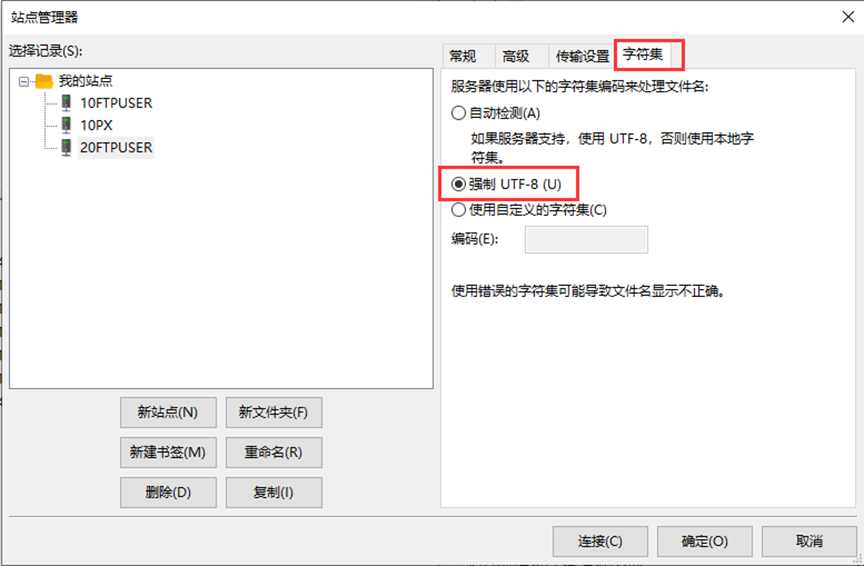
简单操作讲解:(注:分权管理员只拥有自己文件夹的权限,直接默认到对应的文件夹)
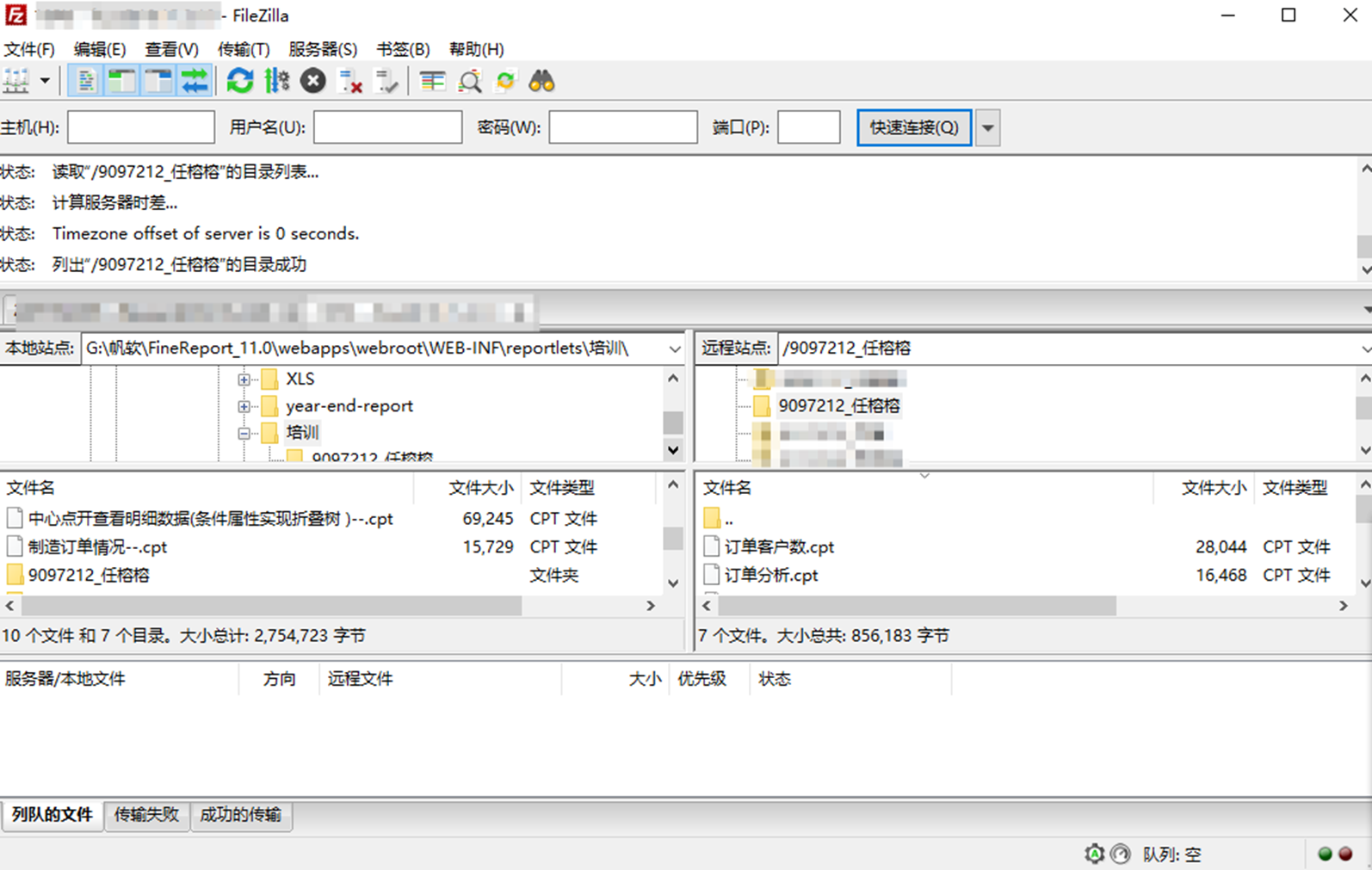
1)、登录:测试机服务器:IP
2)、默认服务器路径:/home/ftpuser/WEB-INF/reportlets
本地显示的路径:例如“培训”文件夹,进放之后看到的是下面对应的文件夹:
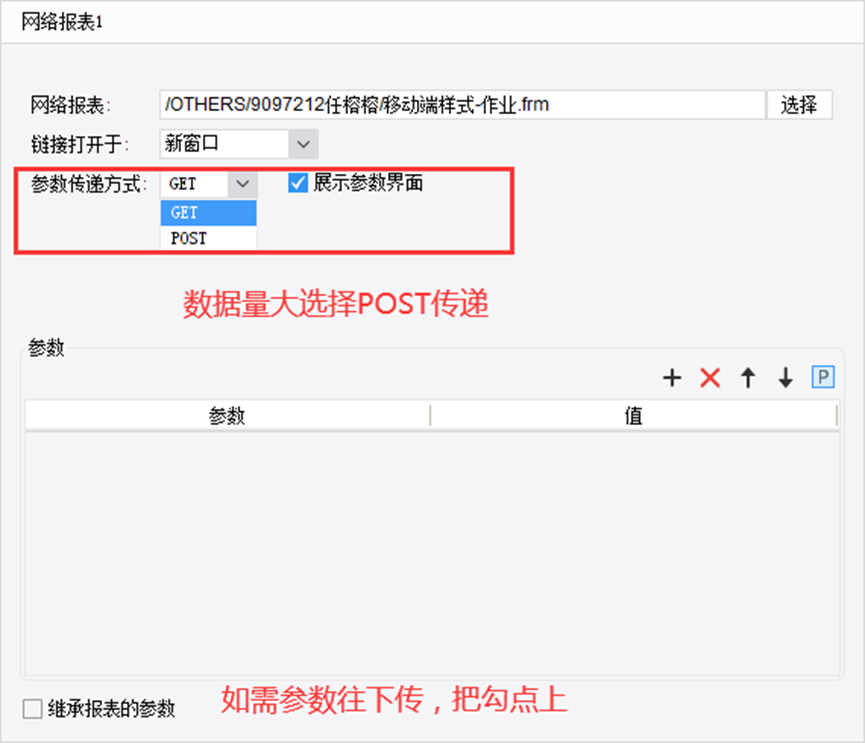
基本跳转说明:
跳转的报表选择:本地和服务器路径设置必须一致,如不一致,会报错-找不到对应的报表。
SQL规范
简介:项目中常用优化策略,文中部分举例的语法为 Oracle 语法,其他
数据库语法参考对应的逻辑来实现。针对本章的内容,需要掌握以下能力:
(1) 了解数据库运算时基础的内存、硬盘交互,
(2) 了解数据表扫描,基于对扫描的理解来提升 SQL 执行效率,
(3) 了解执行计划,掌握到这一层级可以满足 90%项目的需求。
基本理念:当我们执行 SQL 查询语句时,数据库的操作是先根据 SQL 语句从硬盘中
获取数据,然后加载进内存中进行后续计算。由于 SQL 语句有执行的先后顺序,因此当 SQL
一开始查询的数据量越小,加载进内存时间越短,并且整个 SQL 执行也越快。
明确字段,不取多余
解释:只取我们需要的字段,不用的不取。不要随意用“*”来查询全部。
例如:假设 A 表总共有 10 个字段,只需要用到其中两个字段,那么查询语句中只取我们需要的两个字段,速度比查询所有字段的速度快。
大表关联,先做过滤
解释:大表关联查询语句中,做到先过滤再关联。不允许使用 WHERE 来进行关联。提
前过滤好,在硬盘和内存交互上、内存计算上可以节省很多时间。
提取共性,减少重复
解释:SQL 语句中有多处重复的子查询,可以将其提取出来,进行参数化,减少数据库
查询次数。注意,MySQL 低版本不支持 WITH AS 语法。
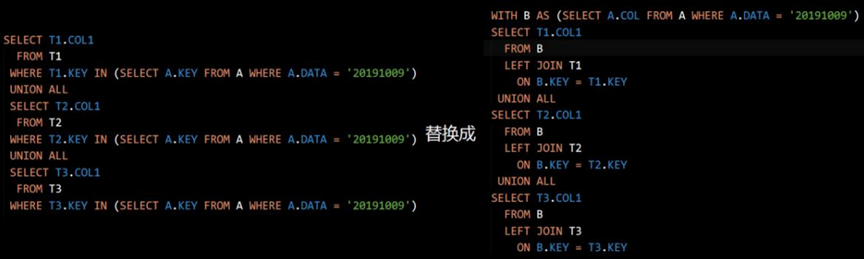
减少不必要的扫描计算。
解释:如果 UNION ALL 可满足要求,就使用 UNION ALL,而不用 UNION,因为 UNION
会有一个比较然后去重的过程,而 UNION ALL 没有。
经常查询的大数据量表,需要创建索引,过滤和排序尽量放在索引列上操作。
解释:索引会提高 SELECT 效率,但是会影响到 INSERT 及 UPDATE 的效率。索引的介
绍及创建方式等内容不在此赘述。
区间范围比较(特别是索引列比较)要有明确边界,降低比较时的计算精度。
解释:用>=、<=代替>、<,。在取值区间±0.00001(或者其他足够小的值)即可实现
代替,例如:
(1)数值比较,A>1 替换成 A>=1.00001
(2)时间比较,A>2019-09-01 00:00:00 替换成 A>=2019-09-01 00:00:00+0.0001
(3)日期比较,A>2019-09-01 替换成 A>=2019-09-02
如果不做替换,数据库计算 A>1 时,可能会一直计算到 A>1.000000000000 才能得出
A>1 的结论,这是浪费计算时间。
避免显式转换、隐式转换导致索引失效。
解释:避免数据库运算时对索引列进行转换,
例如:
(1)显示转换举例,假设索引列为日期型数据,和字符串型日期比较。
错误写法:TO_CHAR(T.索引列,'YYYYMMDD')>='20190715',
这里是用函数将索引列由日期类型转换为字符串类型,导致索引失效。
正确写法:T.索引列 >=TO_DATE('20190715',’YYYY-MM-DD’)
(2)隐式转换举例,假设索引列是一串字符串型的数字,取索引列值为 1 的数据。
错误写法:T.索引列=1
这里是数据库用隐式转换将索引由字符串类型转换成数值类型,导致索引失效。
正确写法:T.索引列=’1’
大表查询时,避免子查询中的排序计算,排序需放在执行计划最后一步。
解释:尽量在子查询中避免 ORDER BY、DISTINCT 等语句。其中 ORDER BY 是对结果进
行排序,而 DISTINCT 和 GROUP BY 是在计算过程中排序。子查询数据量较大时用 EXISTS 子
句代替 DISTINCT。
决策报表中,尽量将多个数据集合并为同一个数据集,减少并发数量。
解释:一个数据集就是一个并发,数据集过多导致并发过高,数据库加载压力大,计算
效率会降低。可以用以下方案减少决策报表中的数据集数量:
(1)将 A、B、C 三个指标的每月/每日的趋势,以年月/年月日为条件进行关联,而不
是每个指标单独一个数据集。
(2)查询结果为一条记录的数据集,直接关联在一起,例如三个数据集 A、B、C 都返
回一条记录,那么可以如下图进行数据集合并处理。
P.S.:报表中控件的数据字典如果数据量过大,并且涉及到控件联动,此时将一个数据
集拆开成多个数据集可以提高控件加载效率,与本条规则相违背,需要酌情考虑。
不常使用,参考建议
简介:在项目中不太常用的几条优化建议,仅作参考,不做规范要求。
1)使用表连接替代 EXIST
2)使用 WHERE 过滤替代 HAVING
3)对于复合索引,WHERE 子句中必须包含索引的第一列才一定能够使用到索引
4) 可对索引列使用 LIKE ’xxx%’,避免对索引列使用 LIKE ’%xxx%’,’%xxx’
5)索引列计算尽量避免对索引列使用 IN、OR 等,可以考虑用 UNION ALL 代替
高阶优化
简介:本章主要用在数据量非常大的情景下,SQL 优化已经无法满足性能要求时使用。
1) 分区分表
解释:将一个表分成若干部分,减少单次扫描的数据量,提升效率,例如将五六年的数据按
年分表存储,单次查询只扫描一年的数据,但是跨年分析会有影响;
2) 数据压缩
解释:即做数据预处理,先定期在数据库里计算好,然后报表中直接取结果数据来展示,例
如将每分每秒的数据汇总成一天一条记录,这种就是做数仓/数据集市;
3) 硬件提速
解释:即用 GP、HANA 等高性能数据库,提高数据运算速
忘记管理员密码,如何找回?
如忘记客户端管理员密码:
本地找到对应路径:用记事本或者编辑器打开:
对应盘\FineReport_10.0\webapps\webroot\WEB-INF\embed\finedb下的db.script文件,
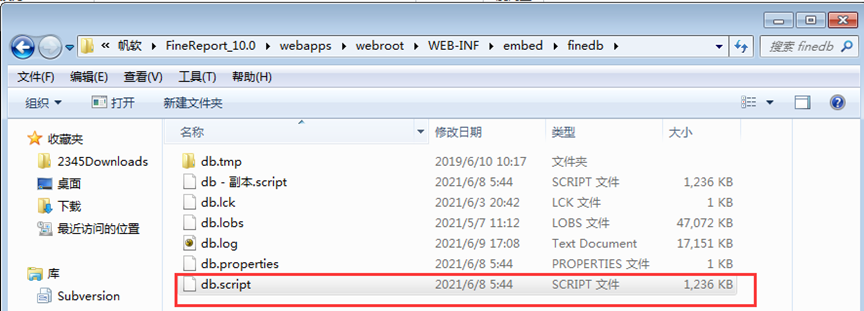
找到这条进行调整:
INSERT INTO FINE_CONF_ENTITY VALUES('SystemConfig.serverInit','success')
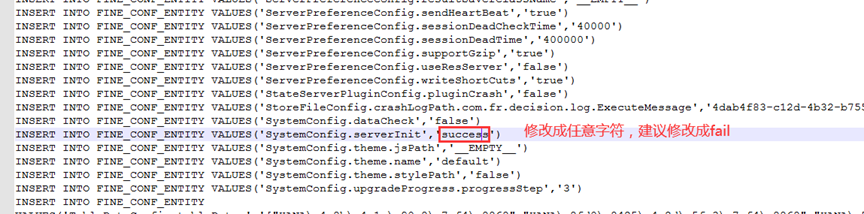
修改完之后登录本地管理员界面:http://localhost:8075/webroot/decision/login?
会出现需要新输入账号密码的界面,重新设置账号密码即可。
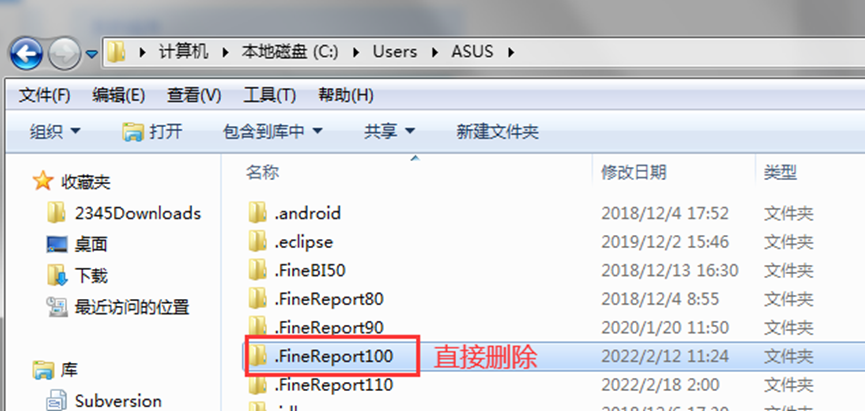
本地设计器打不开,或者打开异常处理
找到自己本地C盘——用户——找到自己用的账号进去,找到对应帆软的版本,可直接剪贴到其它地方,或者直接删除,再开启帆软设计器。
本标准主要制订人(/修订人):任榕榕
| 
 ,所以我们现在没有测试环境,已发布的报表开发人员可以直接修改
,所以我们现在没有测试环境,已发布的报表开发人员可以直接修改
